
Linux内核源码分析
作者:网络转载 发布时间:[ 2013/3/25 13:50:23 ] 推荐标签:
通过这一步的注释,我们基本上能完全把握待分析代码整体的实现机制了。而所有的分析工作可以认为完成了80%。这一步工作尤其关键,我们必须尽量让注释的信息足够的准确,才能更好的理解待分析代码的内部模块的划分。虽然Linux内核中使用了宏语法“module_init”和“module_exit”声明模块文件,但是对模块内部子功能的划分是建立在充分了解模块的功能基础上的。只有正确划分好模块,我们才能弄清模块提供了哪些外部函数和变量(使用EXPORT_SYMBOL_GPL或者EXPORT_SYMBOL导出的符号)。才能继续下一步的模块内标识符依赖关系分析。
第五步:模块内部标识符依赖关系
通过第四步对代码模块的划分,我们可以很“轻松”地逐个对模块进行分析了。一般的,我们可以从文件底部的模块出入口函数开始(“module_init”和“module_exit”声明的函数,一般都在文件后),根据它们调用的函数(自己定义的或者其他模块的函数)和使用的关键变量(本文件内的全局变量或者其他模块的外部变量)画出“函数-变量-函数”依赖关系图——我们称为标识符依赖关系图。
当然,模块内标识符依赖关系并非是单纯的树形结构,很多情况是错综复杂的网络关系。这时候,我们对代码的详细注释的作用体现出来了。我们根据函数本身的含义,将模块进行子功能划分,抽取出每个子功能的标识符依赖树。
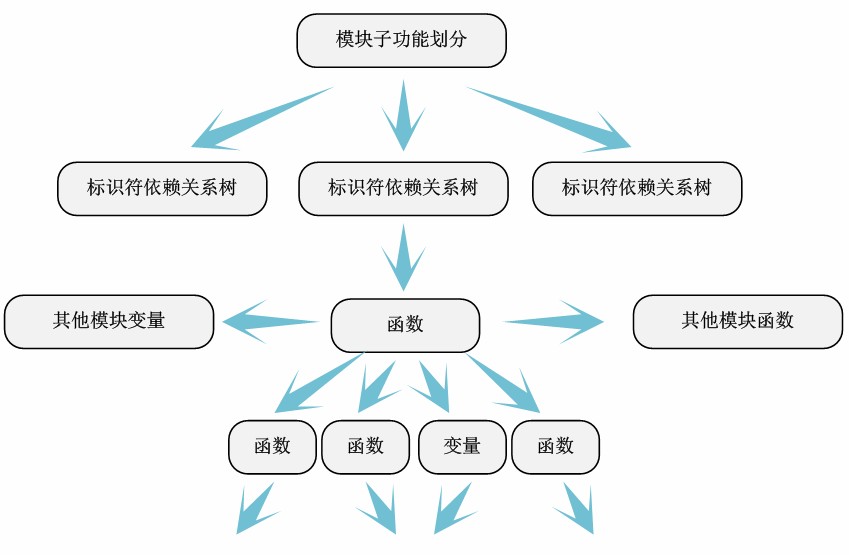
通过标识符依赖关系分析,可以很清晰的展示模块定义的函数调用了那些函数,使用了哪些变量,以及模块子功能之间的依赖关系——公用了哪些函数和变量等。
第六步:模块间相互依赖关系
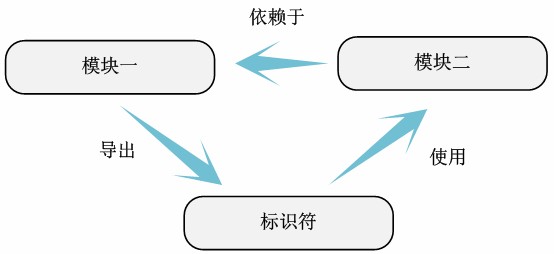
一旦将所有的模块内部标识符依赖关系图整理完毕,根据模块使用的其他模块的变量或函数,可以很容易得到模块之间的依赖关系。
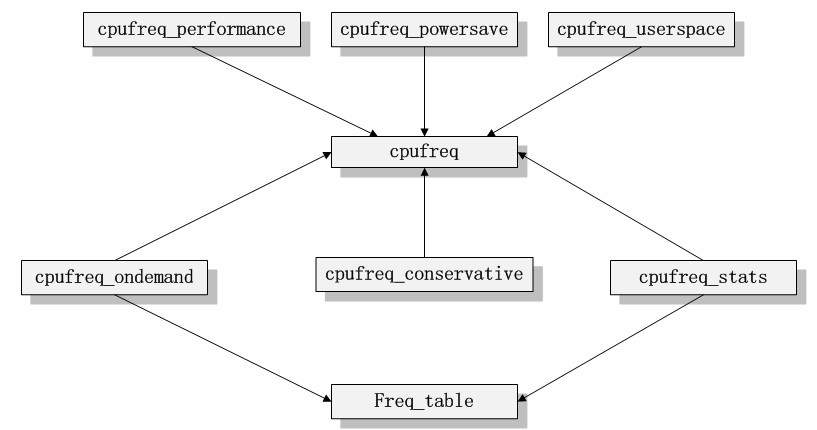
cpufreq代码的模块依赖关系可以表示为如下关系。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com