
Linux内核源码分析
作者:网络转载 发布时间:[ 2013/3/25 13:50:23 ] 推荐标签:
比如在cpufreq.c文件开始会出现“DEFINE_PER_CPU”宏的使用,我们通过查阅资料可以基本弄清这个宏的含义和功能。这里使用的手段和之前搜集资料使用的方法基本一致,另外我们也可以使用sourceinsight提供的转到定义等功能查看它的定义,或者使用LKML(Linux Kernel Mail List)查阅,实在不行我们还可以到www.stackoverflow.com提问寻求解答(想了解什么是LKML和stackoverflow?搜集资料吧!)。总之利用所有可能的手段,我们总能得到这个宏的含义——为每个CPU定义一个独立使用的变量。
我们也不要强求一次能把注释描述的很准确(我们甚至都没必要弄清每个函数的具体实现流程,只要弄清大致功能含义即可),我们结合搜集到的资料和后边代码的分析不断的完善注释的含义(源码中原有的注释和标识符命名在此很有利用价值)。通过不断的注释,不断的查阅资料,不断的修改注释的含义。

当我们把所有涉及的源码文件简单注释完毕后我们可以达到如下效果:
1、基本弄清了源码中代码元素存在的含义。
2、找出了该模块所涉及的基本上全部的关键源码文件。
结合之前搜集到的信息和资料对该待分析代码的整体或者架构描述,我们可以将分析的结果和资料对比,以确定和修正我们对代码的理解。这样,通过一遍的简单注释,我们可以从整体上把握了源码模块的主要结构。这也达到了我们简单注释的基本目的。
第四步:详细注释
完成代码的简单注释后,可以认为对模块的分析工作完成了一半了,剩下的内容是对代码的深入分析和彻底理解。简单注释总是不能将代码元素的具体含义描述的十分精确,因此详细注释是十分有必要的。这一步中,我们需要弄清以下内容:
1、变量定义在何时被使用。
2、宏定义的代码何时被使用。
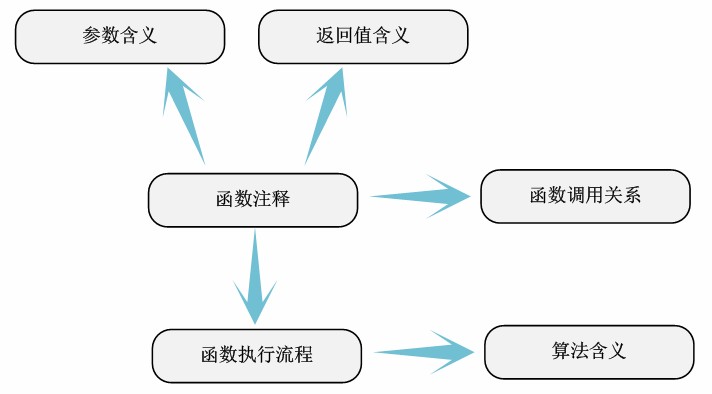
3、函数的参数和返回值的含义。
4、函数的执行流程和调用关系。
5、结构体字段的具体含义和使用条件。
我们甚至可以把这一步称为函数详细注释,因为函数之外的代码元素的含义基本上在简单注释中已经比较明确了。而函数本身的执行流程、算法等是这部分注释和分析的主要任务。
比如cpufreq_ondemand策略的实现算法(函数dbs_check_cpu中)是如何实现的。我们需要逐步分析该函数使用的变量和调用的函数等信息,弄清算法的来龙去脉。好的结果,我们需要这些复杂函数的执行流程图和函数调用关系图,这是直观的表达方式。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com