假设更大的聚合也是可能的,但是我实在不想再考虑了!
每个用例的工作量
通过对每一层的额定的规模的工作量估计,我们可以对每个用例的工作量有一些深入了解。使用 Estimate Professional? 工具 (基于 COCOMO 2 和 Putnam's SLIM 模型),将语言设置为 C++(其他成本驱动因素设置为额定值),然后计算每一个示例系统类型在每个额定规模点的工作量(假设 10 个外部用例),得到表 1。表中描述的 L1 和 L2 范围考虑到了单个用例的复杂度――使用 COCOMO 的代码复杂性矩阵通过类比进行估计。在 L2 层,我相信复杂性在被纳入系统类型的特征时复杂程度发生变化,因此一个更高层次的复杂命令和控制系统用例,将包含在一个较低的层次上复杂性的混合。在一个按照 log-log 比例的图上绘制这些数据,得到图 2。
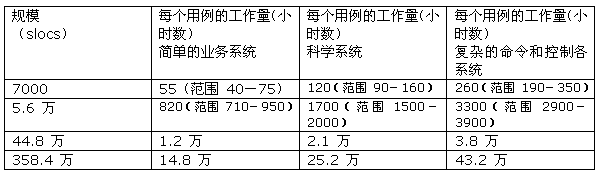
图 2: 用例工作量规模图
从中我们可以看到,150-350 小时/用例(10 2.17-10 2.54)这个原来的 Objectory 数字在 L1 层上很适合,例如,这些用例可以通过类的协作来实现――因此存在一些理由来支持这个数字。然而,它不足以在分析中用来描述所有项目--我的一位同事曾在电子邮件与我交流时说:它太"片面" 了。
工作量估计
当前的实际系统不能与这些槽(slot)一一匹配。所以,为了帮助了解应该如何描述一个系统,我们将使用从该方法种得出的模糊的界限并将它们绘制出来:
图 3: 每个层次的规模范围
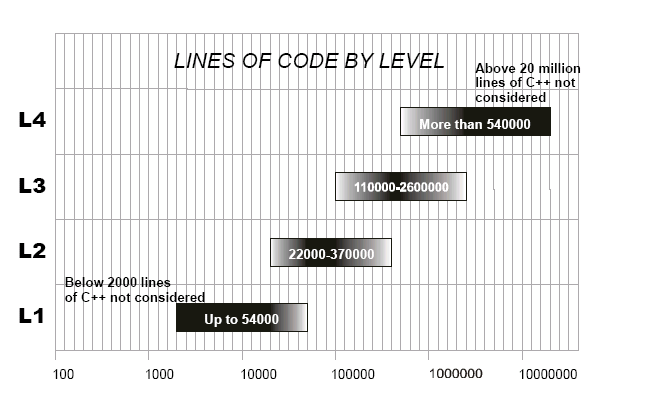
从图 3 中,我们可以看到一个超过 2.2 万 slocs 的系统可能是在第一层描述,用例的数量在 2 到 30 之间。在这个规模上,更高的用例数量表明用例的粒度太细了。
规模在 2.2 万 和 5.4 万 slocs 之间的系统,应该使用一层用例和两层用例的混合,用例的数量在 4(都在第二层)和 76 都在第一层)之间,正如上图所表明的那样,一般不会出现极限值。
规模在 5.4 万和 11 万 slocs 之间的系统,一个结构好的系统完全在第二层进行描述是可能的,用例的数量在 10 到 20 之间;混合起来可能是 L1/L2/L3(1 到 160 个用例,一般不会出现极限值)。
规模在 11 万 和 37 万 slocs 之间的系统,可能在第二层和第三层之间,用例的数量在 3(全部在第三层)到 66(全在部第二层)之间。
规模在 37 万 和 54 万 slocs之间的系统,如果完全在第三层进行描述,那么用例的数量在 9 到 12之间;混合情况可能是 L2/L3/L4(1 到 100 个用例,一般不会出现极限值)。
规模在 54 万 和 260 万 slocs 之间的系统,可能在第三层和第四层之间,用例的数量在 2(全部在第四层)到 60(全部在第三层)之间。
规模超过 260 万 slocs 的系统,在第四层的用例数量应该在 8 左右。
多少用例才是足够的?
从一些经验法则中可以得到一些有趣的观察结果。有一个问题经常被问及--多少用例是过量的呢?这个问题实际上意味着在捕获需求的过程中多少是过量。答案似乎是多于 70 个,甚至对于大的系统来说,70 这个数字也表明对于设计来说粒度太细了。在 5 到 40 之间是非常合适的,但是这只是数量,而并没有考虑到层次,不能用来估计规模和工作量。这是初始的数量,对于特殊的层次是合适的。如果一个大型超级系统被分解为系统,系统又被分解为子系统,以此类推,那么需要数以百计的用例。如果直到类的层次达到后才开发用例,那么终的数量可能是上百个甚至是上千个(对于一个 140 人-年的项目,或者对于每个用例有15个功能点这样的项目来说是 600 个用例)。然而,作为一个纯粹的独立于设计的用例分解来说,这并不会发生。这些用例起源于 Jacobson 97 中描述的过程,Jacobson 97 中系统层次上的用例被划分为分配给子系统的行为,其中可以为子系统编写更低层次的用例(将其他子系统作为参与者)。
工作量估计的过程
如何进行估计呢?这里有许多先决条件:如果不能理解问题的领域、不了解系统的规模和系统构架,以及在哪一阶段进行估计,那么不能够进行基于用例的估计。
第一次粗略的估计可以根据专家的观点或者更正式的采用 Wideband Delphi 技术(该技术是Rand 组织在 1948 年发明的,请参考Boehm 81 的描述)。这将使得评估者可以将系统在图 3 所示的规模范围中对号入卒。这种部署将提供用例数量的范围,并且表明表达式的层次(L1, L1/L2 等等)。然后评估者必须基于对现有构架知识和领域中的理解来决定这些用例是否适合某一层(是否毫不相关),或者是不同层次的混合(以事件流的方式来表达)。

