类和子系统在 UML 中定义为;在 UML 中更大的聚合是子系统(包含子系统),为了更简单的进行描述,我进行了不同的命名。对于那些知道 2167 和 498 军方标准(称子系统为 CSC,称类为 CSU)中的术语的人来说,子系统组(subsystemGroup)的规模用 CSCI -来表示。我记得,经过 2167 天的关于 Ada 的结构应该映射到哪一层次的争论后,尘埃落定,Ada 包通常映射为 CSU。我并不建议系统必须严格的遵循这种层次结构,还将存在层次之间的混合,这种层次结构使我能够更好地了解规模对于每个用例工作量的影响。
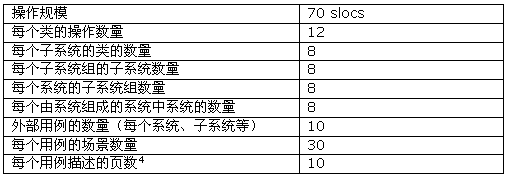
在每一层上都会有用例(尽管对于单个的类可能不是这样),但并不是单纯的大量细节堆砌 ,而是用例针对那个层上的每个组件(例如子系统、子系统组,等等)。在上文中我曾断言对于每一层的每一个组件都有 10 个用例――如果用例的描述平均是 10 页,那么将会给出一个潜在的、大约 100 页长度的说明文档(还要加上类似的或者少一些的关于非系统性需求的相应说明),这是 Stevens 98 提倡的数字,并且和Royce98推荐的数字很接近。但是为什么是 10 个用例呢?为了得出这个数字,基于对每一个子系统的类的数量、类的规模、操作规模等等我认为的合理的规模,我进行了自下向上的推理。这些和其他假设共同搜集在下表中供大家引用。
我没有大量的经验数据-贯穿文中的是琐碎的、分散的数据,Lorentz 94 和 Henderson-Sellers 96 有一些数据,我也有一些在澳大利亚的项目中得出的数据,主要是在军用航空航空领域。任何情况下,在这个阶段,将框架或多或少的定位到合适的位置是非常重要的。
分层结构中组件的大小
这里我应该指出的是,我曾经使用代码行来度量组件的大小,但许多人不喜欢这种度量。这些是 C++(或者相同层次的语言)代码行,所以,要回到功能点非常容易。
在容器中的类的数目和能表达的行为的丰富性之间肯定有许多关系。我选择了 8 个类/子系统 ,8 个子系统/子系统组,8 个子系统组/子系统,等等。那么为什么是 8 个呢?
1. 它在 7 或-2 之间;
2. 由于每个类有 850 slocs(每 70 slocs 有 12 个操作)的 C++代码,它得出了一个子系统的规模是 7000 slocs-一个可以由小的团队(3-7人)在 4-9 个月能够交付的功能/代码的程序块,其中系统的迭代长度该调整到 30 万-100 万slocs (RUP 99) 的范围内 。
那么,多少用例能够表达八个类的行为(外部的)?,哪些是属于子系统的并且已经被定位在子系统中了?决定丰富性的原因不仅仅是用例的数量,还有每个用例的场景数量。现在,并没有多少方法来指导场景/用例扩展――在Booch 98中,Grady Booch 指出"存在一个从用例到场景的"膨胀系统",一个复杂度适当的系统中可能有几十个用于捕获系统行为的用例,每个用例可能具有几十个场景….",Bruce Powel Douglass 在 Douglass 99 中指出,"….为了详细描述用例需要很多场景,通常需要1打到几打"。我选择了 30 个场景/用例――这处于"几打"的较低的一边,但是 Rechtin(在 Rechtin 91中)指出,工程师能够处理 5 到 10 个互相作用的变量(对于这个变量,我解释为互相协作的 5 到 10 个类)并且 10 到 50 种交互(我解释为场景)。以这种方式解释,多个用例即为该变量空间的多个实例。
因此,10 个用例,每个用例 30 个场景,也是说一共 300 个场景(后面将导致大约 300 个测试用例)对于覆盖 8 个类的有意义的行为来说已经足够了。是否有其他的迹象表明这是个合理的数字呢?如果应用 Pareto 的 80-20 规则,那么20%的类将表达80%的功能,同样,80% 的功能将被每个类中20%的操作来表达。让我们保守的说,我们需要20%的类(等)来达到75%的功能并且通过这点来构建一个 Pareto 分布图。(图 1)
图 1: 一个 Pareto 式样的分布图
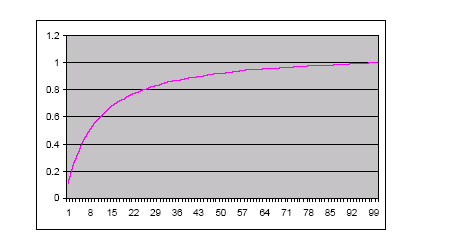
如果我们想要描述 80% 的系统行为,并且将 Pareto 规则应用到类、操作和场景数量方面,那么对于每一者都需要描述其行为的 93%(0.933= 0.8)--也是对于每一个都需要 50%,例如,4 个类和 5 个操作(= (12 - 2 构建器/析构器)/2)。节点树的不同分叉的数量可能达到数千个(其中节点树用来代表4个类及每个类5个操作的执行模式)。我为每个节点创建了 1 到 3 个链接,假设在顶层有 10 个操作(接口操作)的层次结构,并且形成了一个三层的树。这将会有 1000 条路径或者场景。所以,500 个场景将会得到 93% 的覆盖。使用 300 个场景(用相同的假定)我们可以得到 73% 的覆盖。根据一个选定的算法,可以对这个树进行修剪,从而删除冗余的行为说明,甚至更少的数量完全可以符合要求。
达到该目的的另一个方法是研究一下对于 7000 slocs 的 C++代码需要多少测试用例(从场景派生而来)。这些测试用例不受单元测试层次的制约,并且在 Jones 91 和 Boeing 777 项目中有许多证据表明这个数字是安全的,至少它符合实践。这些来源表明在 250 到 280 之间是合适的。在一个完全不同的层次上,加拿大自动空中交通系统(Canadian Automated Air Traffic System ,CAATS)项目使用了 200 项系统测试(我私下里获悉的)。
用例的规模
用例应该具有多大规模呢?是否应该足够大以及表达足够的细节才能表达所需要的行为--这取决于与系统有关的用例复杂性、内部用例和外部用例。--这里我们应该描述多少系统的内部动作来深入探讨一下这个问题。很明显,从外部行为描述来构建系统,要求将输出与输入关联起来。例如,如果行为对历史记录敏感并且很复杂,那么在没有系统内部的一些概念模型及行为的动作时,很难描述它。注意,没有必要描述一个系统是如何从内部构建的--任何满足非功能性需求和匹配模型行为的设计能够满足要求。
UML 1.3 中提供的定义是:"用例【类】:一个系统可以执行的动作(包括变体)序列的说明,其中这些动作与系统参与者进行交互"。对复杂的行为的内部动作,可能合理的采用这个定义也可以在实现阶段再进行定义――这对于终用户来说是个更远的步骤。业务规则也应该纳入到用例中以便约束参与者的行为(例如,在一个ATM系统中,银行需要有一条规则:在一次交易中,提取的金额不能超过 500 美元,无论账号中的余额为多少)。
根据这种解释,事件的用例流描述的页数可以为 2-20 。从计算的角度上看,具有简单行为的系统显然不需要冗长的描述。或许我们可以认为简单的商务系统通常用 2 到 10 页来描述,平均为 5 页。对于更复杂的系统来说,业务系统和科学系统在 6 到 15 页之间,平均为 9 页。复杂的命令和控制系统在 8 到 20 页之间,平均为 12 页(这些比率反映了相同规模系统的工作量与类型之间的非线性关系),尽管我没有数据来支持这种观点。更富有表达力和描述性的形式(例如状态机或者活动图)可能需要更少的篇幅--我们仍旧倾向于加强文本,所以此处不讨论其他形式,毕竟相关资料很少或者根本没有。
与上述规模有系统差异的开发应该运用乘法规则来计算在这些假设基础上得出的每个用例的小时数(我建议增加一个 COCOMO -样式的成本驱动,该驱动是系统类型的(简单的业务类型、更复杂的类型、命令及控制类型等等)的观察到的平均规模或建议的平均规模。
用例规模的另一个方面是场景的数量。例如,一个 5 页长的用例可能是一个具有很多路径的复杂结构。再一次重申,需要将场景的数量以及这个比例估计为 30(这是我对于每个用例的场景数的初步估计),将其作为成本的驱动因素。
得到的结果是,我们假设基于大约长度为 100 页说明的用例,对于任何给定层次的外部说明及补充说明来说,都是足够的。范围是 20 到 200 页之间(这些界限是模糊的)。注意,一个系统(子系统组)在低的层次上的总数是 3-15 页/ ksloc(简单的业务系统)到 12-30 页/ ksloc(复杂的命令和控制系统)。这或许能够解释 Royce 98 表中的 14-9 和实际项目之间明显的矛盾之处,前者的工件所占用的篇幅非常少,而实际项目却占用了大量的页。本文的观点认为规格说明的层次不应受页数的限制。--Royce 是正确的,对于大型的、复杂的系统而言,重要内容的说明(如版本声明)可以达到范围的上限――200 页

