
高可用性系统在大众点评的实践与经验
作者:网络转载 发布时间:[ 2016/3/4 14:21:34 ] 推荐标签:软件测试 可用性测试
成年时期:水平拆分(2015至今)
使命:系统要能支撑大规模的促销活动,订单系统能支撑每秒几万的QPS,每日上千万的订单量。
2015年的917吃货节,流量高峰,如果我们仍然是前面的技术架构,必然会挂掉。所以在917这个大促的前几个月,我们在订单系统进行了架构升级和水平拆分,核心是解决数据单点,把订单表拆分成了1024张表,分布在32个数据库,每个库32张表。这样在可见的未来都不用太担心了。
虽然数据层的问题解决了,但是我们还是有些单点,比如我们用的消息队列、网络、机房等。举几个我过去曾经遇到的不容易碰到的可用性问题:
服务的网卡有一个坏了,没有被监测到,后来发现另一个网卡也坏了,这样服务挂了。
我们使用 cache的时候发现可用性在高峰期非常低,后来发现这个cache服务器跟公司监控系统CAT服务器在一个机柜,高峰期的流量被CAT占了一大半,业务的网络流量不够了。
917大促的时候我们对消息队列这个依赖的通道能力评估出现了偏差,也没有备份方案,所以造成了一小部分的延迟。
这个时期系统演进为下图这样:

未来:思路仍然是大系统做小,基础通道做大,流量分块
大系统做小,是把复杂系统拆成单一职责系统,并从单机、主备、集群、异地等架构方向扩展。
基础通道做大是把基础通信框架、带宽等高速路做大。
流量分块是把用户流量按照某种模型拆分,让他们聚合在某一个服务集群完成,闭环解决。
系统可能会演进为下图这样:
上面点评交易系统的发展几个阶段,只以业务系统的演进为例。除了这些还有CDN、DNS、网络、机房等各个时期遇到的不同的可用性问题,真实遇到过的有:联通的网络挂了,需要切换到电信;数据库的电源被人踢掉了,等等。
易运营
高可用性的系统一定是可运营的。听到运营,大家更多想到的是产品运营,其实技术也有运营——线上的质量、流程的运营,比如,整个系统上线后,是否方便切换流量,是否方便开关,是否方便扩展。这里有几个基本要求:
可限流
线上的流量永远有想不到的情况,在这种情况下,系统的稳定吞吐能力非常重要了,高并发的系统一般采取的策略是快速失败机制,比如系统QPS能支撑5000,但是1万的流量过来,我能保证持续的5000,其他5000我快速失败,这样很快1万的流量被消化掉了。比如917的支付系统是采取了流量限制,如果超过某一个流量峰值,我们自动返回“请稍后再试”等。
无状态
应用系统要完全无状态,运维才能随便扩容、分配流量。
降级能力
降级能力是跟产品一起来看的,需要看降级后对用户体验的影响。简单的比如:提示语是什么。比如支付渠道,如果支付宝渠道挂了,我们挂了50% ,支付宝旁边会自动出现一个提示,表示这个渠道可能不稳定,但是可以点击;当支付宝渠道挂了 ,我们的按钮变成灰色的,不能点击,但也会有提示,比如换其他支付渠道(刚刚微信支付还挂了,又起作用了)。另一个案例,我们在917大促的时候对某些依赖方,比如诚信的校验,这种如果判断比较耗资源,又可控的情况下,可以通过开关直接关闭或者启用。
可测试
无论架构多么完美,验证这一步必不可少,系统的可测试性非常重要。
测试的目的要先预估流量的大小,比如某次大促,要跟产品、运营讨论流量的来源、活动的力度,每一张页面的,每一个按钮的位置,都要进行较准确的预估。
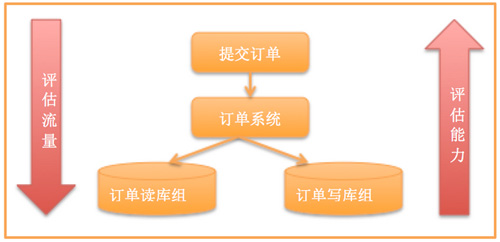
此外还要测试集群的能力。有很多同学在实施的时候总喜欢测试单台,然后水平放大,给一个结论,但这不是很准确,要分析所有的流量在系统间流转时候的比例。尤其对流量模型的测试(要注意高峰流量模型跟平常流量模型可能不一致)系统架构的容量测试,比如我们某一次大促的测试方法
从上到下评估流量,从下至上评估能力:发现一次订单提交有20次数据库访问,读写比例高峰期是1:1,然后跟进数据库的能力倒推系统应该放入的流量,然后做好前端的异步下单,让整个流量平缓地下放到数据库。












 sales@spasvo.com
sales@spasvo.com