
Hadoop平台中SQL优化的四个思路
作者:网络转载 发布时间:[ 2016/12/27 10:58:48 ] 推荐标签:SQL Server 数据库
要正确的优化SQL,必须能快速定位性能瓶颈点,或者说快速找到SQL主要的开销所在。慢的设备通常是瓶颈点的成因,如文件下载时的瓶颈点可能是网络速度,本地文件复制时的瓶颈点可能在于硬盘性能。
为了快速找到SQL的性能瓶颈点,首先需要读者对各种设备的性能数据有一些基本的认识,如千兆网络带宽是1000Mbps,硬盘转速为每分钟7200/10000转等。
下图数据给出了一些当前主流的计算机性能指标。
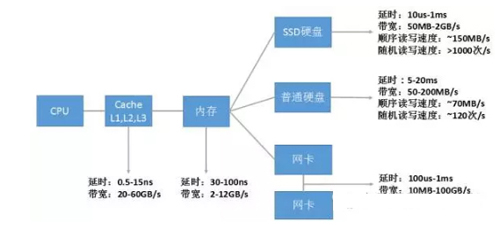
图1 I/O各层次硬件性能汇总
如上图所示,每种设备基本上都有两个重要指标:
· 延时(响应时间):反映硬件的突发处理能力。
· 带宽(吞吐量):反映硬件持续处理能力。
通过比较这两种指标,可以发现计算机各系统硬件性能从高到低依次为:CPU→Cache(L1-L2-L3)→内存→SSD硬盘→网络→硬盘。
比较性能之后,我们再看一下每种硬件在Hadoop系统进行SQL运算时负责的主要工作:
CPU及内存:缓存数据访问、比较、排序、事务检测、SQL解析、函数或逻辑运算、JOIN、数据加解密、加解压等;
网络:结果或者Shuffle数据的传输、SQL请求、远程数据访问等;
硬盘:数据访问、数据写入、日志记录、外排序、Shuffle等。
将以上陈列的各硬件性能指标及其工作内容结合考虑,在Hadoop集群中提升SQL的执行性能是要尽量做到以下四点:
1、减少数据访问(减少磁盘访问)
2、减少中间结果量(减少网络传输或磁盘访问)
3、减少交互次数(减少网络传输、减少调度开销)
4、改进算法,减少服务器CPU开销(减少CPU及内存开销)
注:实际优化时,除了以上四点还应注意任务分配要均匀且大小适中。
总而言之,优化的基本思想是反复迭代,合理利用资源,综合平衡各种开销,以求达到优效果。下面将简单介绍这四种优化思路,以及分别可采用的方法。
1. 减少数据访问
传统关系型数据库例如MySQL、Oracle等,通常通过提供索引来实现减少数据访问、提升访问速度,但是由于Hadoop不维护键(Key)的特性,因而SQL on Hadoop引擎一般不提供对传统索引的支持,或者功能不像传统索引一样完备。
为了达到和索引相似的优化目的,即加快过滤扫描,SQL on Hadoop产品通常提供其他功能用以弥补。以星环科技的Inceptor为例,其本身并没有可用于控制的传统意义上的索引,但是提供了分区、分桶,以及MinMaxFilter、BloomFilter以及RowFilter等用于批量过滤数据的过滤器。这些功能的原理通常是通过把相似、相关或者相等的数据进行归类以减少查询搜索的范围,或者建立基于列式存储的扫描方式尽可能的减少无关数据的读取。使用者需要结合实际语句,把这些功能进行高效组合,合理运用在刀刃上。
2. 返回更少的数据
返回更少的数据是要求在构造SQL语句时,只SELECT需要的列。因为每个字段的提取都是一个复杂的解析过程,且占用内存,所以为了减少不必要的查询时间,请读者好仅返回需要的字段。比如减少“SELECT *”的使用,因为大多数情况是不需要所有字段的数据的。
【例1】如果某用户提交了这样的语句,但是实际需要的只有id、name两个字段:
SELECT * FROM product WHERE company_id = 456723
LIMIT 100;
为了加快执行速度,建议将语句写为:
SELECT id, name FROM product
WHERE company_id = 456723
LIMIT 10;
另外若SELECT的结果是用于判断某些条件是否成立,例如EXISTS操作,更加没必要返回所有数据:
【例2】某个包含关联的语句,在优化调整前,EXISTS内部返回了满足条件的所有字段值:
SELECT … FROM table_name_2 WHERE
… EXISTS (
SELECT * FROM table_name_1
WHERE table_name_1.col1 = table_name_2.col1
);
但是EXISTS的返回仅用于判断满足条件的记录存在与否,所以EXISTS内部无需返回所有字段。因此可以将EXISTS子句中的“SELECT *”优化为“SELECT 1”:
SELECT … FROM table_name_2 WHERE
… EXISTS (
SELECT 1 FROM table_name_1
WHERE table_name_1.col1 = table_name_2.col1
);
3. 减少交互次数
减少交互次数是减少网络通信的交互次数。这里分享与此相关的三种优化情况。
Batch DML
批量方式处理DML可以大幅度减少和服务器的交互次数。Inceptor数据库访问框架提供了批量提交的接口以服务于大量插入数据。当用户一次性往一个表中插入1000万条数据时,试想如果采用普通的Insert,将和服务器发生1000万次交互,按每秒钟向数据库服务器提交10000次估算,完成所有工作需要消耗1000秒。但是如果采用批量提交模式,每1000条提交一次,和服务器的交互次数减少至1万次,交互次数大大减少,耗时缩短为原来的千分之一。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com