
高并发Web服务演变:节约系统内存和CPU
作者:网络转载 发布时间:[ 2015/4/20 10:46:29 ] 推荐标签:WEB测试 内存 CPU 服务
以简单的磁盘读写例子,从磁盘中读取A文件,写入到B文件。A文件数据是从磁盘开始,然后载入到“内核缓冲区”,然后再拷贝到“用户缓冲区”,我们才可以对数据进行处理。写入的时候,也同理,从“用户态缓冲区”载入到“内核缓冲区”,后写入到磁盘B文件。
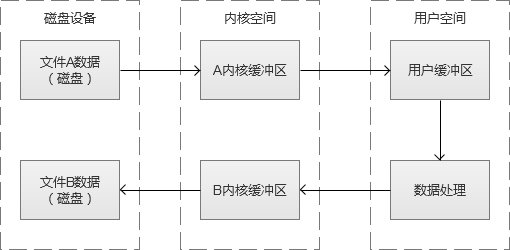
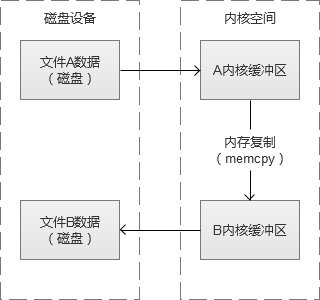
这样写文件很累吧,于是有人觉得这里可以跳过“用户缓冲区”的拷贝。其实,这是MMP(Memory-Mapping,内存映射)的实现,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”,而是返回一个指向内存空间的指针。于是,我们之前的读写文件例子,会变成,A文件数据从磁盘载入到“内核缓冲区”,然后从“内核缓冲区”复制到B文件的“内核缓冲区”,B文件再从”内核缓冲区“写回到磁盘中。这个过程,减少了一次内存拷贝,同时也少内存占用。
好了,回到sendfile的话题上来,简单的说,sendfile的做法和MMP类似,是减少数据从”内核态缓冲区“到”用户态缓冲区“的内存拷贝。
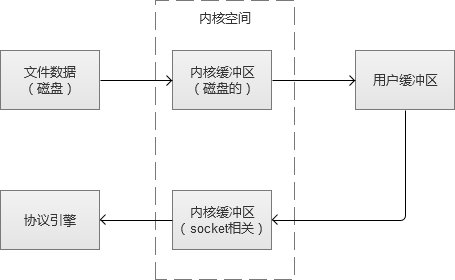
默认的磁盘文件读取,到传输给socket,流程(不使用sendfile)是:
使用sendfile之后:
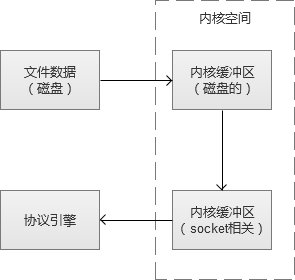
这种方式,不仅节省了内存,而且还有CPU的开销。
四、节约Web服务器的CPU
对Web服务器而言,CPU是另一个非常核心的系统资源。虽然一般情况下,我们认为业务程序的执行消耗了我们主要CPU。但是,Web服务程序而言,多线程/多进程的上下文切换,也是比较消耗CPU资源的。一个进程/线程通常不能长期占有CPU,当发生阻塞或者时间片用完,无法继续占用CPU,这个时候,会发生上下文切换,CPU时间片从老进程/线程切换到新的。除此之外,在并发连接数目很高的场景下,对这些用户建立的连接(socket文件描述符)状态的轮询和检测,也是比较消耗CPU的。
而Apache和Nginx的发展和演变,也在努力减少CPU开销。
1.Select/Poll(Apache早期版本的I/O多路复用)
通常,Web服务都要维护很多个和用户通信的socket文件描述符,I/O多路复用,其实是为了方便对这些文件描述符的管理和检测。Apache早期版本,是使用select的模式,简单的说,是将这些我们关注的socket文件描述符交给内核,让内核告诉我们,那些描述符可操作。Poll与select原理基本相同,因此放在一起,它们之间的区别,不赘叙了哈。
select/poll返回的是一个我们之前提交的文件描述符集合(内核将其中可读、可写或者异常状态的socket文件描述符的标识位修改了),我们需要通过轮询检查才能获得我们可以操作的文件描述符。在这个过程中,不断重复执行。在实际应用场景中,大部分被我们监控的socket文件描述符,都是”空闲的“,也是说,不能操作。我们对整个集合轮询,是为了找了少部分我们可以操作的socket文件描述符。于是,当我们监控的socket文件描述符越多(用户并发连接数越来越多),这个轮询工作,也越来越沉重,进而导致增大了CPU的开销。
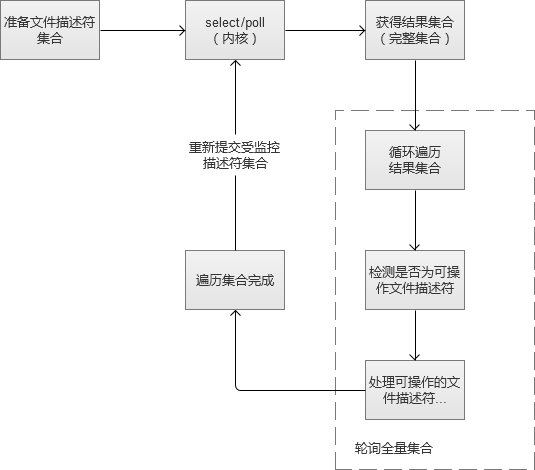
如果我们监控的socket文件描述符,几乎都是”活跃的“,反而使用这种模式更合适一点。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com