
一种C/C++代码安全静态检测模型
作者:网络转载 发布时间:[ 2013/12/24 13:14:55 ] 推荐标签:C C++ 代码 静态检测
显然,扩充以后的分析过程,能很好地应对带逻辑分支的代码段。尽管实际工程中的代码远远要复杂得多,但大多情况不过是各种顺次控制逻辑的组合。正确地应用这种上下文分析技术,应该能够相对快速地分析代码中的漏洞,并确保一个较低的误报率。
1、模型化
在传统静态分析中,风险库是引起各种安全漏洞的API的集合,而词法匹配通过对源代码进行扫描,可以对风险API定位,这些恰好是上下文分析的第一步。在上下文分析的第二、三步中,需要跟踪变量的使用情况,即对变量的初始定义以及其后的再定义、表达式引用、函数调用情况、作链表记录。而在第四步中,要得到程序的分支走向,需要了解的是语句之间的控制依赖关系,恰恰这些工作与编译器的数据流分析以及控制流分析部分相关,故这里引入一些编译原理的概念和技术,提取上下文信息。
构造相应的安全检测模型如下:
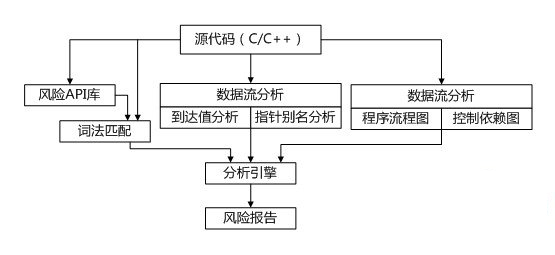
2、到达定值分析
编译原理中,到达定值是这样一个概念:定值是对x的赋值或读值到x的语句。称a 定值d 到达程序点P,若存在路径从紧跟d 的点到达P,且在这条路径上d 没有被注销。如果沿着这条路径的某两点间是读值到a或对a的赋值,那么注销变量a 的那个定值(应该是指d)。定义这样一个结构:
|
Struct _VARNODE { int iLineNO; int iValue; bool fSet; } |
在每一个变量出现的地方, 生成这么一个节点。其中iLineNO记录行号信息,若当前语句对于该变量是赋值操作,则将fSet设置为true,并将新值记录到iValue中;否则, fSet设置为false, iValue无效。将所有该变量的节点添加到一个链表,可以得到该变量在整个工程的使用情况。这样,可以通过链表查找某行API调用时,该变量值域是否在限制之内。
3、指针别名分析
对同一个存储地址存在多条访问路径,会出现别名问题。访问路径是通过变量及一些运算符生成的表达式。例如 *p、i、&a 、s →next,这些表达式都是访问路径。只有进行确切指针别名分析,才能对变量的赋值操作作准确的定位。对于语句*p = i,访问路径*p与i别名,这个别名关系可以用一个二元组〈*p, i〉来表示。定义结构如下:
|
Struct _ARIASNODE { String varorg; String varpointer; } |
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com