
Linux探秘之I/O效率
作者:网络转载 发布时间:[ 2016/6/14 10:40:47 ] 推荐标签:操作系统 Linux
2、标准I/O:属于ISO C实现的标准库函数,调用的是底层的系统调用。
(1) 将逻辑单元中的数据写入文件,根据需求,有三种函数类型可以调用,以fputc、fputs、fwrite为例,这些函数不用人为去控制缓冲区的大小,而是系统自动申请的,当用户定义了相应的I/O函数之后,根据不同的缓存类型(是全缓冲、行缓冲还是无缓冲),系统自动调用malloc等函数申请缓冲区,即标准I/O缓存。
(3)(5) 当用户缓冲区满了之后,如系统I/O操作一般,此时调用write从标准I/O缓存中复制数据到内核缓冲区,再写入磁盘。
(4)(6) 同系统I/O操作,从内核缓冲区调用read读入到用户缓冲区。
(2) 同样有三种函数类型可以调用,以fgetc、fgets、fread为例,读入逻辑单元进行后续的处理。
可见,标准I/O实现的机制是基于系统I/O,这样看来,标准I/O在效率上肯定不如系统I/O,但事实是标准I/O与系统I/O相比并不慢很多,而且还有很多其他的优点,下面一一述说(本篇文章重要的是下一小节)。
五、I/O效率
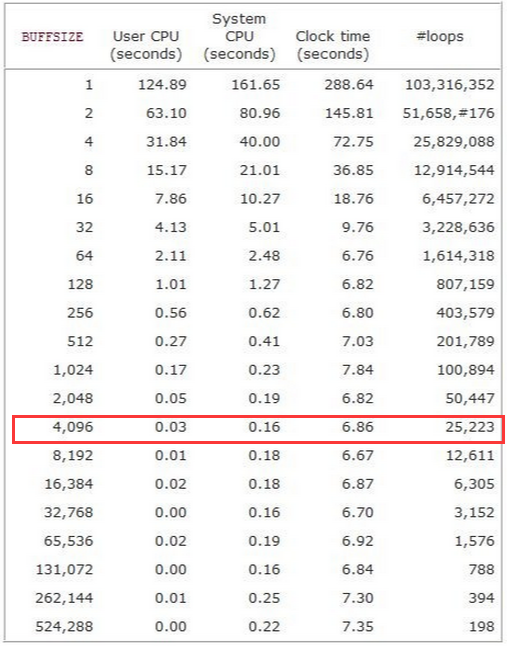
系统I/O效率受限于read、write系统调用的次数,而系统调用次数则又受限于内核缓冲区的大小,即BUFFSIZE,通过设置不同的BUFFSIZE,系统CPU时间是不同的,其小值出现在BUFFSIZE=4096处,原因是该测试所采用的是Linux ext2文件系统,其块长为4096字节,也即缓冲区所能申请到的大缓冲区大小,我们把4096字节看做是本次佳I/O长度。如果继续扩大缓冲区大小,对此时间几乎没有影响。所以,对于系统I/O操作,一个大的问题是:需要人为控制缓存的大小及佳I/O长度的选择,另外是系统调用与普通函数调用相比通常需要花费更多的时间,因为系统调用具体内核要执行这样的操作:1)内核捕获调用,2)检查系统调用参数的有效性,3)在用户空间和内核空间之间传输数据。
因此,引入标准I/O的目的是为了通过标准I/O缓存来避免BUFFSIZE选择不当而带来的频繁的系统调用。根据用户不同的需求,选择不同的I/O函数,然后根据不同的缓存类型,自动调用malloc等缓存分配函数分配合适的缓存,等分配的缓存满之后,再调用系统I/O从标准I/O缓存向内核缓存拷贝数据,这样进一步减少了系统调用的次数。
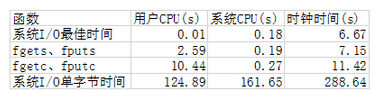
但是不同的标准I/O函数,不同的缓存类型也会带来不同的效率。如上图,当选择系统佳I/O长度,即BUFFSIZE的大小和文件系统的块长一致,可以得到佳的时间。当选用标准I/O函数时,每次一个字符函数fgetc、fputc和每次一行函数fgets、fputs函数相比要花费较多的CPU时间,而每次单个字节调用系统I/O则花费更多的时间,如果是一个100M的文件,则要执行大概2亿次函数调用,也引起2亿次系统调用(从用户缓冲区到内核缓冲区,再到磁盘),而fgetc版本也执行了2亿次函数调用,但只引起了大约25222次系统调用,所以,时间大大减少了。
综合以上,标准I/O函数虽然基于系统I/O实现,但很大程度上减少了系统调用的次数,而且不用人为关心缓冲区大小的选择,整体上提高了I/O的效率。另外,标准I/O提供了多种缓存类型,方便程序员根据不同的应用需求选择不同的缓存要求,提高了编程的灵活性,当选择无缓存时,相当于直接调用系统I/O。
OK,大概的内容以上这些,当然关于I/O操作这块还有很多需要注意的点,而且还有很多更加高级的I/O函数,这些在后面遇到再来做总结。后,如果您觉得这篇文章对您有帮助粉我吧,还是那句话,你的关注是我写作的大动力。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com