
MySQL排序原理与案例分析
作者:网络转载 发布时间:[ 2016/3/22 10:45:43 ] 推荐标签:数据库 MySQL
假设每页3条记录,第一页limit 0,3和第二页limit 3,3查询结果如下:

我们可以看到 id为4的这条记录居然同时出现在两次查询中,这明显是不符合预期的,而且在5.5版本中没有这个问题。产生这个现象的原因是5.6针对limit M,N的语句采用了优先队列,而优先队列采用堆实现,比如上述的例子order by c1 asc limit 0,3 需要采用大小为3的大顶堆;limit 3,3需要采用大小为6的大顶堆。由于c1为2的记录有3条,而堆排序是非稳定的(对于相同的key值,无法保证排序后与排序前的位置一致),所以导致分页重复的现象。为了避免这个问题,我们可以在排序中加上值,比如主键id,这样由于id是的,确保参与排序的key值不相同。将SQL写成如下:
select * from t1 order by c1,id asc limit 0,3;
select * from t1 order by c1,id asc limit 3,3;
案例2
两个类似的查询语句,除了返回列不同,其它都相同,但排序的结果不一致。
测试表与数据:
create table t2(id int primary key, status int, c1 varchar(255),c2 varchar(255),c3 varchar(255),key(c1));
insert into t2 values(7,1,'a',repeat('a',255),repeat('a',255));
insert into t2 values(6,2,'b',repeat('a',255),repeat('a',255));
insert into t2 values(5,2,'c',repeat('a',255),repeat('a',255));
insert into t2 values(4,2,'a',repeat('a',255),repeat('a',255));
insert into t2 values(3,3,'b',repeat('a',255),repeat('a',255));
insert into t2 values(2,4,'c',repeat('a',255),repeat('a',255));
insert into t2 values(1,5,'a',repeat('a',255),repeat('a',255));
分别执行SQL语句:
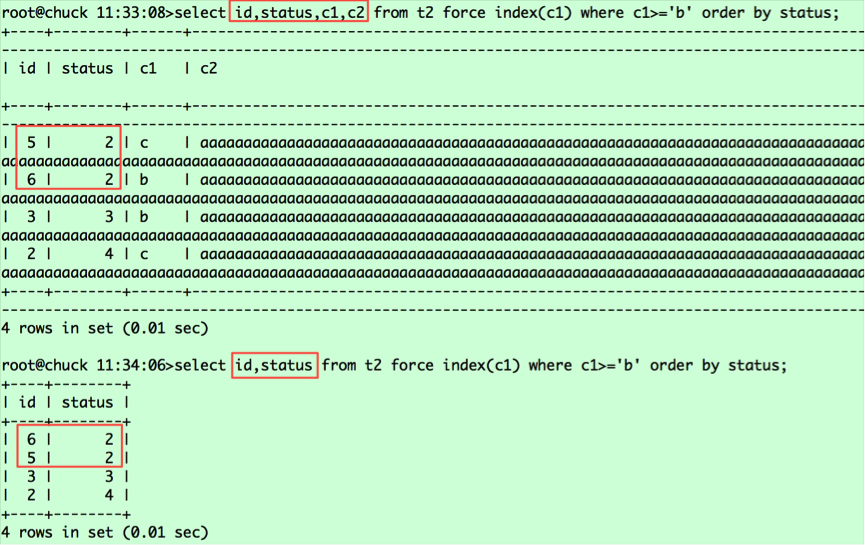
select id,status,c1,c2 from t2 force index(c1) where c1>='b' order by status;
select id,status from t2 force index(c1) where c1>='b' order by status;
执行结果如下:
看看两者的执行计划是否相同

为了说明问题,我在语句中加了force index的hint,确保能走上c1列索引。语句通过c1列索引捞取id,然后去表中捞取返回的列。根据c1列值的大小,记录在c1索引中的相对位置如下:
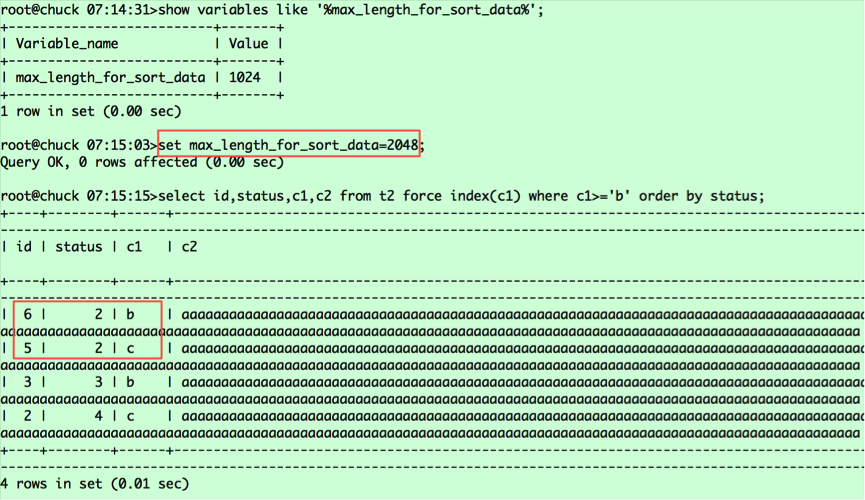
(c1,id)===(b,6),(b,3),(5,c),(c,2),对应的status值分别为2 3 2 4。从表中捞取数据并按status排序,则相对位置变为(6,2,b),(5,2,c),(3,3,c),(2,4,c),这是第二条语句查询返回的结果,那么为什么第一条查询语句(6,2,b),(5,2,c)是调换顺序的呢?这里要看我之前提到的a.常规排序和b.优化排序中标红的部分,可以明白原因了。由于第一条查询返回的列的字节数超过了max_length_for_sort_data,导致排序采用的是常规排序,而在这种情况下MYSQL将rowid排序,将随机IO转为顺序IO,所以返回的是5在前,6在后;而第二条查询采用的是优化排序,没有第二次捞取数据的过程,保持了排序后记录的相对位置。对于第一条语句,若想采用优化排序,我们将max_length_for_sort_data设置调大即可,比如2048。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com