
MySQL数据库主从复制架构
作者:网络转载 发布时间:[ 2016/1/22 13:50:39 ] 推荐标签:数据库
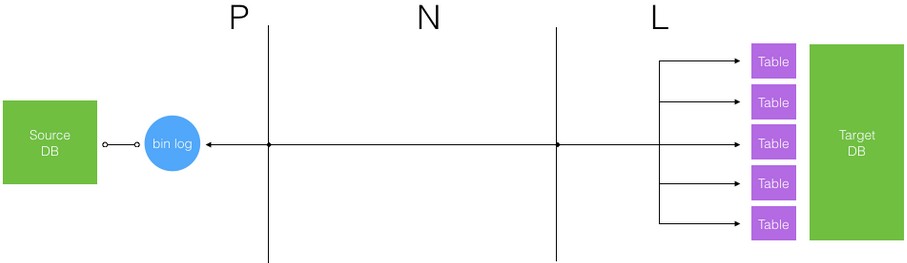
Pull Worker,作用类似于原生的 I/O Thread。
Buffer + Persistent Storage,作用类似于原生的 Relay log。
Load Worker,作用类似于原生的 SQL Thread。
由于是自定义程序实现则可以在无改造 MySQL 的前提下提供额外的功能,相对应用和 MySQL 都可以做到透明。相对原生复制架构的不足,自定义复制架构可以提供更好的复制过程监控和管理能力,并支持异构数据转换等等。而对于需要跨地域、跨机房且延时敏感的大型库复制,则可以通过适当的策略来加速复制过程。
比如前面提到的大型电商的订单、交易类数据库,一般都是分库分表的。分库分表后,不同库表之间的数据其实在业务上是完全独立的,是可以支持并行写入的。所以我们看上图为什么画了两个 Load Worker,是表达可以针对业务独立的表进行并行写入。一条数据的复制延时包括:
总时长 T = P + N + L; 其中 P 是 Pull Worker 处理时长,N 是网络传输时长, L 是 Load Worker 处理时长。
同一个库的 binlog 是顺序的不好并行拉取,传输过程的网络时长也是刚性的,能加速的是入库处理。按业务独立的不同表可以做到并行的多线程入库操作,以缩短 L 的整体时长,如下图所示。
总结
本文分析了 MySQL 基于 binlog 的主从复制原理,从数据一致性的角度考虑分布式网络环境下主从架构设计的关键要素。在分析了 MySQL 原生复制架构的基础上给出了一个灵活性和可控性更高的自定义复制架构的高层设计。理解了主从复制架构如何保证数据一致性后,我们后面才可进一步考虑在双写主库的场景如何做双向复制同步并保证双主库的数据终一致性问题。这个系列下一篇文章会专门分析这个问题。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系SPASVO小编(021-61079698-8054),我们将立即处理,马上删除。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11热门文章
常见的移动App Bug??崩溃的测试用例设计如何用Jmeter做压力测试QC使用说明APP压力测试入门教程移动app测试中的主要问题jenkins+testng+ant+webdriver持续集成测试使用JMeter进行HTTP负载测试Selenium 2.0 WebDriver 使用指南

 sales@spasvo.com
sales@spasvo.com