
我是如何击败Java自带排序算法的
作者:网络转载 发布时间:[ 2015/9/6 11:14:28 ] 推荐标签:测试开发技术 编程语言
Java 8 对自带的排序算法进行了很好的优化。对于整形和其他的基本类型, Arrays.sort() 综合利用了双枢轴快速排序、归并排序和启发式插入排序。这个算法是很强大的,可以在很多情况下通用。针对大规模的数组还支持更多变种。我拿自己仓促写的排序算法跟Java自带的算法进行了对比,看看能不能一较高下。这些实验包含了对特殊情况的处理。
首先,我编写了一个经典的快速排序算法。这个算法通过计算样本的平均值来估计整个数组的中心点,然后用作初始枢轴。
我借鉴了一些Java的思路来适当改进我的快速排序,修改后的算法在对小数组进行排序的时候直接调用了插入排序。在这种情况下,我的排序算法和Java的排序算法可以达到相同的运行时间量级。Wild & al 指出,如果排序数组有很多的重复数据,标准的快速排序会比双枢轴的快速排序要快。我没有尝试任何字节或汇编级别的分析和优化。在大部分的问题中,我的版本的优化程序都远远不能跟Java系统程序相提并论。
我一直都想测试脑海里的一个简单的排序算法,我称之为Bleedsort。这是一个分布式算法,它通过样本抽样方法对要排序的数组进行分布估计,根据估计结果把数据分配到相应的一个临时的数组里(如图 1 所示),并重写这个初始的数组。这是一个预处理过程,然后再应用其他的排序算法分别进行排序。在我的测试中,我使用了我编写的快速排序版本。如果使用合并排序应该会有更好的结果,因为合并排序被广泛应用在高度结构化的数组中。为了计算简单,我只测试了分布均匀的数据。
Bleedsort在遇到相同的数据的时候都会放到右边,所以此算法在排序相对一致(译者注:会有很多重复数据)的数组的时候表现很差。所以我需要对排序的数组进行样本估计,当重复数很多的情况下应避免使用Bleedsort算法。
我很清楚,Bleedsort算法在内存空间使用方面没办法跟归并排序(快速排序)相提并论,临时数组也比原来的数组要大四倍左右。同时其他的一些分布排序算法,比如Flashsort,在这方面也表现得要好很多。
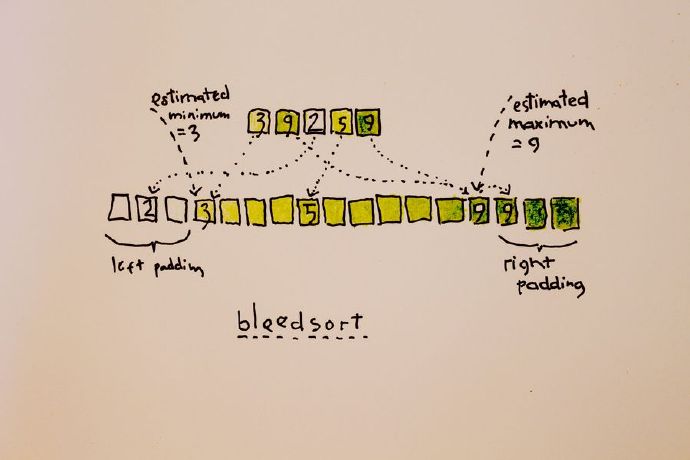
图1 Bleedsort举例说明












 sales@spasvo.com
sales@spasvo.com