
写Java也得了解CPU?CPU缓存
作者:网络转载 发布时间:[ 2015/7/29 16:20:28 ] 推荐标签:测试开发技术 编程语言
以我所使用的Xeon E3 CPU和64位操作系统和64位JVM为例,如这里所说,假设编译器采用行主序存储数组。
64位系统,Java数组对象头固定占16字节(未证实),而long类型占8个字节。所以16+8*6=64字节,刚好等于一条缓存行的长度:
如32-36行代码所示,每次开始内循环时,从内存抓取的数据块实际上覆盖了longs[i][0]到longs[i][5]的全部数据(刚好64字节)。因此,内循环时所有的数据都在L1缓存可以命中,遍历将非常快。
假如,将32-36行代码注释而用25-29行代码代替,那么将会造成大量的缓存失效。因为每次从内存抓取的都是同行不同列的数据块(如longs[i][0]到longs[i][5]的全部数据),但循环下一个的目标,却是同列不同行(如longs[0][0]下一个是longs[1][0],造成了longs[0][1]-longs[0][5]无法重复利用)。运行时间的差距如下图,单位是微秒(us):
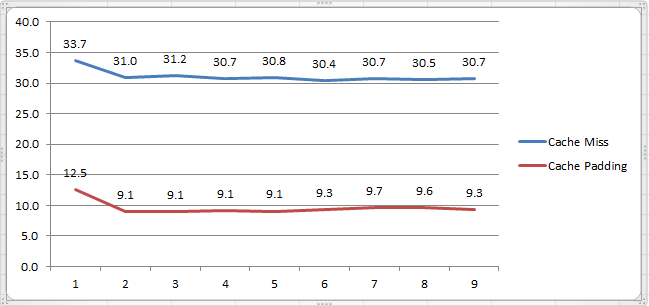
后,我们都希望需要的数据都在L1缓存里,但事实上经常事与愿违,所以缓存失效 (Cache Miss)是常有的事,也是我们需要避免的事。
一般来说,缓存失效有三种情况:
1. 第一次访问数据, 在cache中根本不存在这条数据, 所以cache miss, 可以通过prefetch解决。
2. cache冲突, 需要通过补齐来解决(伪共享的产生)。
3. cache满, 一般情况下我们需要减少操作的数据大小, 尽量按数据的物理顺序访问数据。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系SPASVO小编(021-61079698-8054),我们将立即处理,马上删除。
相关推荐
Java性能测试有哪些不为众人所知的原则?Java设计模式??装饰者模式谈谈Java中遍历Map的几种方法Java Web入门必知你需要理解的Java反射机制知识总结编写更好的Java单元测试的7个技巧编程常用的几种时间戳转换(java .net 数据库)适合Java开发者学习的Python入门教程Java webdriver如何获取浏览器新窗口中的元素?Java重写与重载(区别与用途)Java变量的分类与初始化JavaScript有这几种测试分类Java有哪四个核心技术?给 Java开发者的10个大数据工具和框架Java中几个常用设计模式汇总java生态圈常用技术框架、开源中间件,系统架构及经典案例等











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11热门文章
常见的移动App Bug??崩溃的测试用例设计如何用Jmeter做压力测试QC使用说明APP压力测试入门教程移动app测试中的主要问题jenkins+testng+ant+webdriver持续集成测试使用JMeter进行HTTP负载测试Selenium 2.0 WebDriver 使用指南

 sales@spasvo.com
sales@spasvo.com