
AWR数据库优化案例分享(OLAP)
作者:网络转载 发布时间:[ 2015/12/1 11:22:45 ] 推荐标签:数据库 SQL
分享一个案例,说说如何来看AWR。
提到优化,不得不提AWR?
想起来刚接触Oracle的时候别人问我会不会优化,我说会呀,在高峰时段跑个AWR,然后分析TOP 10 SQL,现在想来,很是汗颜!
经过一段时间的学习,又有了一些不成熟的想法,写了下来,也许再过两年来看得时候,会很有趣!
话不多说,结合案例,进入正文。
一、关于AWR的生成时间跨度问题:
首先:AWR的生成跨度一般不要超过一个小时,超过一个小时则没有参考价值;
其次:AWR的生成跨度在一个小时以内的,好结合ASH来看;
再次:AWR的生成跨度在半个小时以内的,可以不需要ASH;
小贴士:
1、如何生成ASH?
@?/rdbms/admin/ashrpt.sql
2、修改awr生成间隔及保留周期(30分钟,10天)
exec dbms_workload_repository.modify_snapshot_settings(interval=>30,Retention=>10*24*60);
二、第一个参数:DB Time

dbtime是看AWR第一个需要注意的参数,请看上图:(本例中使用的所有图片均为同一个AWR报告)
dbtime的计算公式是:dbtime=cpu核数*60秒=32*60=1920(本例中CPU核数为32)
实际的DB Time超过了1920,那么表示CPU可能达到 了。
三、第二个部分:Load Profile
参数说明:
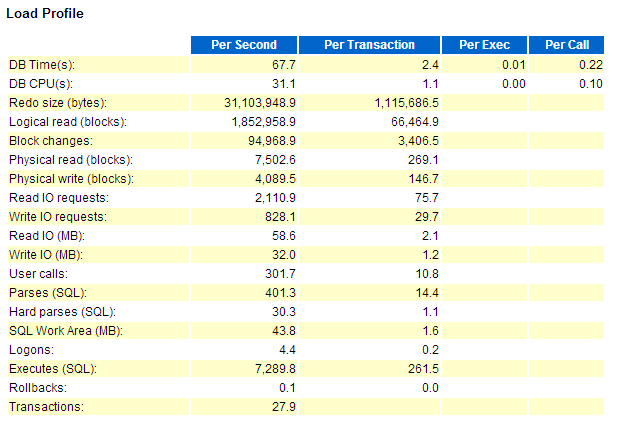
Redo size --单位:Byte;大小:约31M;由此可知此系统的Redo Size 的写入频率为31M/S;
--以此例说明一下redo日志组的大小计算问题:
如果Redo的写入速度是31M/S,那么redo log的大小应该设置为多少?
已知Redo是3秒写入一次的,虽然目前的写入速度是31M/S,但是按照经验我们一般Double一下,Redo log的大小设置为180M左右。
Logic Read --本例逻辑读的单位是块,大小是8K。
--本例中逻辑读为:1852985*8/1024/1024=14.13G /S
--根据与其他DBA的交流经验,一个CPU1秒大概能处理1G左右的数据,那么光逻辑读此系统消耗了15个CPU,占了CPU总数的一半;
Block Change --每秒的块变化数,物理读与物理写还不算特别严重,没有太多IO消耗,每秒读约60M左右的数据;
--看到这里可以得出一个结论了,那是此系统IO不是问题,CPU是问题。
下来看到硬解析,如下图:

Hard parses --硬解析sql 一个CPU大概能支撑10个左右的Hard Parses(SQL),平均30个硬解析sql占用3个CPU
--结论:又增加了CPU负担
四、等待事件:
做优化现在命令率啥的,一般都可以不看了,一般都开等待事件;
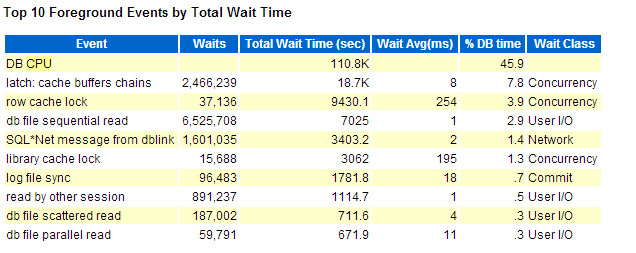
Cache buffer chains --CBC可以理解为热点快,有可能解决CBC的方法是SQL优化;
row cache lock --行缓存锁;
--引起原因有四个
1、sequence没加cache;
2、开了回收站;
3、用多了同义词;
4、递归调用。
--看到这里,猜测可能是回收站引起的问题了,我们接下来再看。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com