
c/c++程序内存空间浅说
作者:网络转载 发布时间:[ 2014/2/18 11:51:09 ] 推荐标签:net 开发 测试技术
一个由C/C++编译的程序占用的内存分为以下几个部分:
1、栈区(stack):又编译器自动分配释放,存放函数的参数值,局部变量的值等,其操作方式类似于数据结构的栈。
2、堆区(heap):一般是由程序员分配释放,若程序员不释放的话,程序结束时可能由OS回收,值得注意的是他与数据结构的堆是两回事,分配方式倒是类似于数据结构的链表。
3、全局区(static):也叫静态数据内存空间,存储全局变量和静态变量,全局变量和静态变量的存储是放一块的,初始化的全局变量和静态变量放一块区域,没有初始化的在相邻的另一块区域,程序结束后由系统释放。
4、文字常量区:常量字符串是放在这里,程序结束后由系统释放。
5、程序代码区:存放函数体的二进制代码。
下图便是unix系统一个进程的内存占用示意图
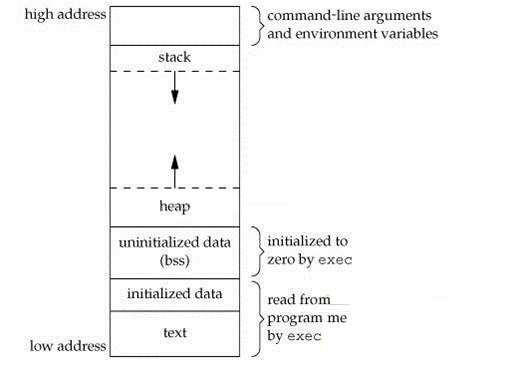
从图中可以看出:
1.从低地址到高地址分别为:代码段、(初始化)数据段、(未初始化)数据段(BSS)、堆、栈、命令行参数和环境变量
2.堆向高内存地址生长
3.栈向低内存地址生长
在实际编程中会遇到的与内存空间相关的问题
1.内存申请
为了解决数据存储的问题,我们有3种办法申请空间并使用它们
第一,从栈空间中申请(即直接定义数组)
第二,从堆空间中申请(使用malloc或者new动态申请内存)
第三,使用文件存储数据
我们主要讨论前两个方案
1、申请后系统的响应:
栈:只要栈的剩余空间大于所申请的空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请的空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样代码中的delete或free语句能够正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会将多余的那部分重新放入空闲链表中。
2、申请的大小限制不同:
栈:在windows下,栈是向低地址扩展的数据结构,是一块连续的内存区域,栈顶的地址和栈的大容量是系统预先规定好的,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域,这是由于系统是由链表在存储空闲内存地址,自然堆是不连续的内存区域,且链表的遍历也是从低地址向高地址遍历的,堆得大小受限于计算机系统的有效虚拟内存空间,由此空间,堆获得的空间比较灵活,也比较大。
3、申请的效率不同:
栈:栈由系统自动分配,速度快,但是程序员无法控制。
堆:堆是有程序员自己分配,速度较慢,容易产生碎片,不过用起来方便。
4、堆和栈的存储内容不同:
栈:在函数调用时,第一个进栈的是主函数中函数调用后的下一条指令的地址,然后是函数的各个参数,在大多数的C编译器中,参数是从右往左入栈的,当本次函数调用结束后,局部变量先出栈,然后是参数,后栈顶指针指向开始存的地址,也是主函数中的下一条指令。
堆:一般是在堆得头部用一个字节存放堆得大小,具体内容由程序员安排。
总结
数据量较小时,推荐使用栈空间申请,即直接定义数组
数据量稍大或者不确定时,推荐使用堆空间内存,即使用malloc或者new动态申请,因为栈空间常常会有大小的限定,当栈空间耗尽时,栈溢出会导致程序崩溃
当数据量超大的,建议重新审阅算法或者使用文件存储
栈空间与子函数,递归与栈溢出
当一个子函数被调用时,子函数的数据及代码都会被装入栈中,因为栈空间通常会有大小限制,如果子函数太多时,会有栈溢出的风险。所以当程序员考虑使用递归函数解决问题时,应当考虑到栈溢出的风险。建议学会使用将递归函数写成非递归函数的方法。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com