
一种正规的性能调优方法:基于等待的调优
作者:网络转载 发布时间:[ 2013/4/24 15:29:28 ] 推荐标签:
基于等待点的分析是一个分析应用中主要请求处理路径的过程,借此定位潜在影响该请求可能会等待的资源。在等待点分析实践中有效的办法是定位并标出应用中核心处理路径。这包括一个请求可能访问的所有层次、请求交互的所有外部服务、被做成池的所有对象和全部缓存对象。
基于层次的等待点
一个请求穿过一个物理层,比如在web层和业务层之间切换,或者调用外部服务器,比如web服务,每当这种时候,都意味着伴随着转换,这里存在一个隐式等待点。如果服务器在某一时刻只处理单个请求是没有效率的,因此他们使用了多线程方法。典型的,一个服务器在某个socket端口监听访问的请求——每当收到一个请求它会把请求放在队列中,然后返回监听其他请求。请求队列对应着一个线程池,负责从队列中提取请求并处理。图2描述了对于三层结构(web服务器、动态web层和业务层)的执行过程。
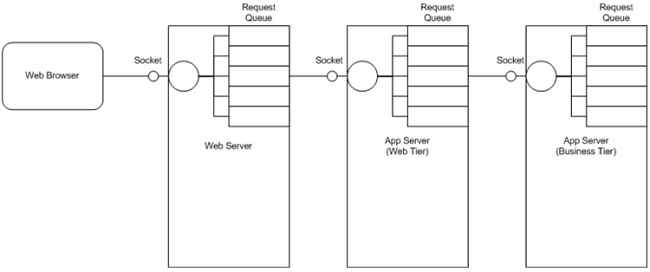
图 2 基于层次的等待点
因为请求穿越层次的动作会引起请求队列,由相应的线程池处理,这种线程池也是一个潜在的等待点。每一个线程池的大小的调优必须基于以下考虑:
池必须足够大使得访问的请求无需不必要的等待一个线程。
池不能大到耗尽服务器。过多的线程会迫使服务器花费大量时间用于在不同的线程上下文中切换,真正处理请求的时间反而更少了。这种情况通常表现为CPU使用率很高,但是处理请求的吞吐量却降低了。
池的大小不能透支与之交互的后台资源。例如,如果数据库对于单个服务器只支持50个请求,那么服务器不应该向数据库发送超过50个数量的请求。
服务器线程池的佳尺寸的标准是:对受限制的依赖资源产生足够的负载—大化它们的使用率而不让其透支。下面的“后退调优”一节有更多调整受限制资源池大小的内容。
基于技术的等待点
基于层次的等待点考虑的是在不同服务器之间传递请求,而基于技术的等待点关注的则是在单个服务器中如何通过有效地内部工作来传递请求。基于层次的调优,类似于IBM的队列调优,只是调整应用的有效第一步,如果忽略了调优应用服务器的内部工作,则会对应用性能产生巨大的影响。这类似于调整JDBC连接池以发送佳数量的负载给数据库,但是忽略了检查执行的SQL语句——如果查询需要连接十个表单,每个表单有一百万个记录,则佳负载可能是两个连接,但是如果我们优化了查询,则数据库可能支持二百个连接。深入研究应用服务器和应用使用的潜在技术,可能存在以下通用的基于技术的等待点:
池对象(比如无状态session bean或者其他应用放入池的业务对象)
缓存设施
持久化存储或外部依赖池
通讯基础设施
垃圾收集
大多数情况下,无状态session bean池的大小被应用服务器优化,不会是一个明显的等待点,除非池大小被手工错误的配置了。但是也存在一些池对象必须手动配置大小——这些可能成为有效的等待点。当一个应用需要一个池化的资源,它必须从池里获取一个资源实例,使用它,然后释放给池。如果池太小,所有的对象实例都在被使用,则请求不得不等待一个实例可用。显而易见,等待一个池化的资源会增加响应时间,如果越来越多的请求被堵塞在等待池化资源,会导致明显的性能下降。另一方面,如果池很大,它可能消耗过多内存,对总体JVM的性能产生差的影响。池的佳大小需要权衡,只能在对池的利用情况做彻底的分析才能决定。
池化对象是无状态的,这意味着应用从池中得到哪个实例都无所谓——任何实例都行。另一方面,缓存的对象都是有状态的,也是说当应用从缓存中请求一个对象时,它的目标是一个特定对象。举一个很粗糙的类比说明一下区别:考虑人们生活当中两种常见的活动:超市购物和接孩子放学。在超市中,任何收银员都可以接待每一位顾客,无论顾客选择哪位收银员都可以顺利结账。因此收银员可以池化。但是在接孩子放学时,每一个父母只想要他们自己的孩子,别的孩子是不行的。因此孩子可以被缓存。
如前面所述,缓存提出了一个新的调优挑战。简单说,缓存的目的是在本地内存中存储对象,使应用可以随时读取它们,而不是在需要的时候才获取他们。一个合适大小的缓存可以对通过远程调用加载对象的行为提供明显的性能改善。但是,一个不合适大小的缓存,可能产生明显的性能阻碍。因为缓存维护有状态的对象,所以重要的一点是在缓存中存储频繁访问的对象,同时保留额外的空间来处理非频繁访问对象。试想如果缓存太小,请求会怎样:
请求检查缓存中是否存在某对象,结果失败。
请求需要查询外部资源获取对象数据。
因为缓存通常维护频繁访问的数据,所以这个新对象需要添加到缓存中(它正在被访问)。
但是如果缓存满了,必须利用“少近访问”算法选择一个对象移除。
如果缓存对象的状态与外部资源不一致,则缓存对象移除之前必须更新外部资源。
新的对象此刻添加到缓存中。
新的对象终返回给请求。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com