
测试工具??Distcp工具深入分析
作者:网络转载 发布时间:[ 2013/11/4 11:11:21 ] 推荐标签:
拷贝过程关键代码如下:
FSDataInputStream in = null;
FSDataOutputStream out = null;
try {
// open src file
in = srcstat.getPath().getFileSystem(job).open(srcstat.getPath());
reporter.incrCounter(Counter.BYTESEXPECTED, srcstat.getLen());
// open tmp file
out = create(tmpfile, reporter, srcstat);
// copy file
for(int cbread; (cbread = in.read(buffer)) >= 0; ) {
out.write(buffer, 0, cbread);
cbcopied += cbread;
reporter.setStatus(
String.format("%.2f ", cbcopied*100.0/srcstat.getLen())
+ absdst + " [ " +
StringUtils.humanReadableInt(cbcopied) + " / " +
StringUtils.humanReadableInt(srcstat.getLen()) + " ]");
}
} finally {
checkAndClose(in);
checkAndClose(out);
}
Mapper执行完之后,DistCp工具的服务端执行过程全部完成了,回到客户端还会做一些扫尾的工作,例如同步Owner权限。这里会有一些问题,稍后我们一并分析。
问题分析
DistCp存在三大问题,下面来一一剖析:
1.任务失败,map task报“DFS Read: java.io.IOException: Could not obtain block”
这是由于“_distcp_src_files”这个文件的备份数是系统默认值,例如hadoop-site.xml里面设置了dfs.replication=3,那么_distcp_src_files文件的备份数则创建之后为3了。当map数非常多,以至于超过了_distcp_src_files文件三个副本所在datanode大容纳上限的时候,部分map task会出现获取不了block的问题。对于DistCp来说“-i”参数一般是不能使用的,因为设置了该参数,这个问题会被掩盖,带来的后果是拷贝完缺失了部分数据。比较好的做法是在计算了总map数之后,自动增加_distcp_src_files这个文件的备份数,这样一来访问容纳上限也会跟着提高,上述问题不会再出现了。当前社区已对此有了简单fix,直接将备份数设置成了一个较高的数值。一般说来对于计算资源有限的集群来说,过多的maptask并不会提高拷贝的效率,因此我们可以通过-m参数来设定合理的map数量。一般说来通过观察ganglia,bytes_in、bytes_out达到上限可以了。
2.Owner同步问题
DistCp工具的提示信息非常少,对于海量数据来说,DistCp初始阶段准备拷贝文件列表和结束阶段设定Owner同步耗时都比较长,但却没有任何提示信息。这是一个很奇怪的地方,拷贝过程中,mapred会打印进度信息到客户端,这时候可以看到百分比,等结束的时候可以看到过程中的一些统计信息。如果你设置了-p参数,此时会处于一个停滞的状态,没有任何输出了。由于Owner同步没有在map task里面去做,放在客户端必然成为一个单线程的工作,耗时也会比较长。我以前犯过的错误是启动distcp后看jobtracker页面出现作业了,kill了客户端的进程,这样一来导致Owner不会同步。现在做法都是用“nohup nice -n 0”把进程放到后台让其自动结束。
3.长尾问题
DistCp切分map的时候,充分考虑了每个map需要拷贝的数据量,尽量保持平均,但是却完全没有考虑碎文件和整块文件拷贝耗时不同的问题。此外,某些task所在tasktracker机器由于故障之类原因也会导致性能较差,拖慢了整体节奏。拷贝大量数据的时候总会因为这些原因出现长尾。通过在InputSplit的时候同时考虑数据量和文件个数的均衡可以解决碎文件和整文件拷贝耗时不同的问题。而部分task运行慢的问题,目前看起来则没有很好的解决方案。
用途
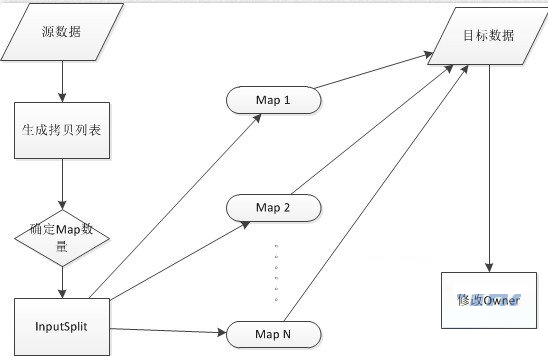
DistCp这个工具不仅可以用来做数据拷贝迁移工作,同时也是一个很好的制造集群负载的工具。用来模拟一定压力下的集成测试是非常有效的。在跨机房项目中,我们使用该工具负载两个机房之间的带宽,通过控制同时工作map数来调整带宽的增减是非常有效的。拓展该工具的代码思路,我们在跨机房项目中制作出来的很多压力测试、性能测试工具也都发挥了作用。下面简单用一幅流程图来说明一下distcp工具的思想:
总结
DistCp工具是一个非常易于使用的拷贝工具,在Hadoop生态圈众多怪兽级应用中,DistCp的代码是优美且短小精悍的。也因为其代码易读性非常好,因此作为MR编程框架的入门教材也非常适合。小心的使用这个工具,我们可以在很多测试场景下模拟真实的线上情况。因此建议每位刚入Hadoop门的码农都能钻研一下DistCp的源码,增加对MR编程框架和HDFS文件系统的深入理解。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com