
性能设计技术之浅谈过载保护
作者:网络转载 发布时间:[ 2012/10/25 10:10:35 ] 推荐标签:
过载保护,看似简单,但是要做好并不容易。这里用两个曾经经历的反面案例,给出过载保护的直观展现,并附上一点感想。
案例一基本情况
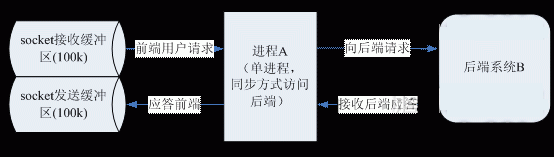
如下图,进程A是一个单进程系统,通过udp套接字接收前端请求进行处理。在处理过程中,需要访问后端系统B,是同步的方式访问后端系统B,根据后端系统B的SLA,超时时间设置是100ms。前端用户请求的超时时间是1s。
进程A的时序是:
Step1: 从socket接收缓冲区接收用户请求
Step2: 进行本地逻辑处理
Step3: 发送请求到后端系统B
Step4: 等待后端系统B返回
Step5: 接收后端系统B的应答
Step6: 应答前端用户,回到step1处理下一个请求
正常情况下的负载
正常情况下:
1、前端请求报文大小约100Bytes。前端请求的峰值每分钟1800次,即峰值每秒30次。
2、后端系统B并行能力较高,每秒可以处理10000次以上,绝大多数请求处理时延在20ms内。
3、进程A在处理请求的时候,主要时延是在等待后端系统B,其他本地运算耗时非常少,小于1ms
这个时候,我们可以看出,系统工作良好,因为处理时延在20ms内,每秒进程A每秒中可以处理50个请求,足以将用户每秒峰值30个请求及时处理完。
导火索
某天,后端系统B进行了新特性发布,由于内部逻辑变复杂,导致每个请求处理时延从20ms延长至50ms,根据sla的100ms超时时间,这个时延仍然在正常范围内。当用户请求达到峰值时间点时,灾难出现了,用户每次操作都是“服务器超时无响应”,整个服务不可用。
过载分析
当后端系统B处理时延延长至50ms的时候,进程A每秒只能处理20个请求(1s / 50ms = 20 )。小于正常情况下的用户请求峰值30次/s。这个时候操作失败的用户往往会重试,我们观察到前端用户请求增加了6倍以上,达到200次/s,是进程A大处理能力(20次/s)的10倍!
这个时候为什么所有用户发现操作都是失败的呢? 为什么不是1/10的用户发现操作能成功呢? 因为请求量和处理能力之间巨大的差异使得5.6s内迅速填满了socket接收缓冲区(平均能缓存1000个请求,1000/(200-20)=5.6s),并且该缓冲区将一直保持满的状态。这意味着,一个请求被追加到缓冲区里后,要等待50s(缓存1000个请求,每秒处理20个,需要50s)后才能被进程A 取出来处理,这个时候用户早看到操作超时了。换句话说,进程A每次处理的请求,都已经是50s以前产生的,进程A一直在做无用功。雪球产生了。
案例二基本情况
前端系统C通过udp访问后端serverD,后端server D的udp套接字缓冲区为4MB,每个请求大小约400字节。后端serverD偶尔处理超时情况下,前端系统C会重试,多重试2次。

正常情况下的负载
正常情况,后端serverD单机收到请求峰值为300次/s,后端serverD单机处理能力是每秒1500次,时延10ms左右。这个时候工作正常。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com