
selenium是目前web和app自动化测试的主要框架。对于web自动化测试而言,由于selenium2.0以后socker服务器由本地浏览器自己启动且直接通过浏览器原生API操作页面,故越来越多的人不再使用selenium RC了。大家使用的大多数是selenium-client,python版本的selenium-client新版本是3.3.3(2017-04-04发布),却忽略了selenium server!事实上在大型的Grid分布式布局中必须要使用selenium server,我也会对这个布局的使用做一些必要的解释。在开始这个话题之前我说明两点内容:
第一、写selenium结合docker的使用只是个缩影,其实我想让大家了解使用docker,你可以不精通但是你得会用!!!
第二、我不太想写一些关于selenium的一些基础操作,如:browser.get(×××),browser.find_element_by_id(×××)....这些大家都会,不会可以查一些文档都会有相应的解释,对我自己而言我想记录的是一些关于比较高级点的话题,或者在自动化过程中遇到的难题(比如上篇操作flash),又或者selenium中大家忽略的一些方法的使用。
废话说了不少,开始我们的话题selenium结合docker构建分布式测试环境。
1.了解Selenium Standalone Server的使用
Selenium Standalone Server目前新的版本是3.3.1(dcoker中selenium/hub这个镜像下载的也是这个新的版本),因为我们的分布式测试环境是基于这个包的使用,我们花一点时间来说说如何使用它。下面是一张Grid分布式布局的基本结构:
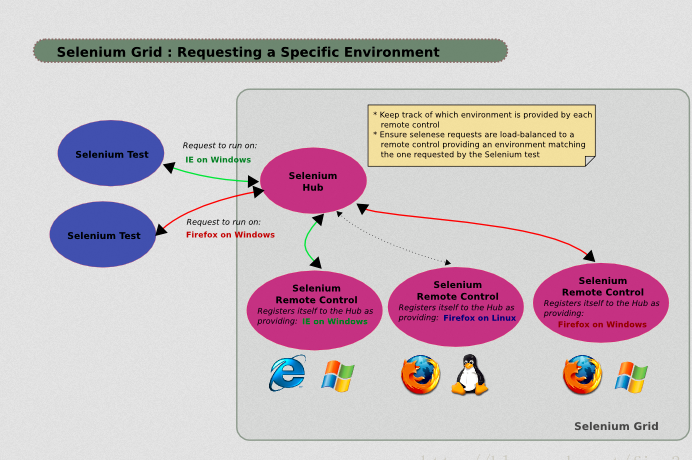
上图中的selenium hub类似于一个中央处理器,selenium node是远程需要执行测试的节点,selenium Test case是运行在hub上的测试用例。
如何启动一个selenium hub?
首先需要java的运行环境,在终端中输入java -jar selenium-server-standalone-x.xx.x.jar -role hub -参数。
关于这个启动的参数其实是需要我们来关注的。我们输入java -jar selenium-server-standalone-2.52.0.jar -role hub -help下面列出来很多启动参数,我相信你应该能看得懂,在下面的介绍中我也会提到一些参数。
如何向selenium hub中注册信息?
在终端中输入java -jar selenium-server-standalone-x.xx.x.jar -role node -参数。
同理,我们输入java -jar selenium-server-standalone-2.52.0.jar -role node -help获取一些启动node的参数说明。
2.了解docker
说完了Grid的一些原理,我们来看看docker关于它的说明自行百度。我对它的简单理解如下:
docker像个货船,货船是干嘛的?装集装箱的! 那么这些集装箱是什么?集装箱是一个个小的容器! 容器是什么? 容器是一个个搭建有简易linux系统的特定应用,比如这个容器只搭建了java环境或者只搭建了apache环境! 容器如何启动它? 通过镜像来启动! 镜像怎么来的? 通过从镜像源pull或者自己构建镜像!
自言自语一会,不知道你是否明白我说什么了,不明白也没关系,我们结合搭建分布式环境这个应用,你应该会明白!
说完了docker是什么,我们着手使用!
1.如何安装docker?
如何安装docker百度上有很多它的说明,由于我的是windows系统,关于它的安装使用推荐文章如下:
http://www.jianshu.com/p/4052926bc12c这篇文章讲述了用docker搭建spalsh服务器,里面有详细的关于docker的安装使用
2.如何获取镜像?
我们用xshell或者CRT连接docker后,执行如下命令:
docker pull selenium/hub,它会自动从镜像源中下载新的selenium/hub镜像
docker pull selenium/node-firefox,它会自动从镜像源中下载新selenium/node-firefox镜像
当然可以用docker pull selenium/node-chrome下载selenium/node-chrome的镜像,目前是没有基于IE或者Safari浏览器的镜像,当然我们完全有能力去自己构建这些镜像!这一篇我主要讲基于firefox浏览器的,其他的类似...
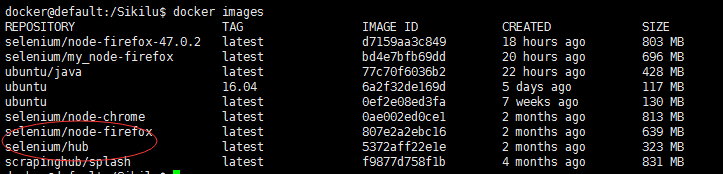
顺便提一句,可以利用docker search+镜像名称能搜索镜像源所存在的镜像名称。当我们下载完这2个镜像后,我们在Xshell中输入docker images应该有如下信息:
3.如何启动这2个镜像?
上文提到了我们先启动一个hub,docker启动命令如下:
Sikilu$ docker run -p 5555:4444 -d --name 'selenium_hub' selenium/hub做一些简单的说明:
run:通过镜像启动一个容器
-p:端口映射,5555是容器宿主机的端口是我们docker这个轮船的端口,4444是我们容器的端口是我们集装箱的端口。这说明了我们把容器的4444端口开放给docker主机的5555端口,那么我们可以通过docker主机的5555端口来访问容器了,有点?嗦~~~
-d:docker后台运行这个容器,我们知道运行server-standalone-2.52.0.jar这个包实际上是启动一个socket程序的,是在一个while循环中的。如果不启用后台运行的话,在xshell当前窗口是不能进行其他的操作的,当然你要再开一个窗口连接docker也可以。
--name:指定容器运行的别名,如果不指定会随机生成一个。
selenium/hub:是我们要运行的镜像文件。
启动完hub后,我们启动一个node,启动node命令如下:
docker run -P -d --link selenium_hub:hub selenium/node-firefox做一些简单的说明:
run:和上文相同
-P:随机生成映射端口号,上文中的-p是指定特定的端口号,这里面是node我们并不需要知道容器内部的端口号,当然你要指定也可以,端口号不要冲突即可。
-d:后台运行与上文相同。
--link:说明我们这个容器是依赖上文中我们生成的容器selenium_hub,后面我们会提到link的使用。
selenium_hub:hub:前面的selenium_hub是我们上文中通过selenium/hub镜像启动容器的别名;后面的hub一定要写成hub或者HUB,写成其他启动失败,为什么这样我们后面会和--link一起说明。
selenium/node-firefox:node的镜像。
启动了selenium/hub与selenium/node后,我们运行docker ps有如下信息:

我们看出来相应的一些启动信息。
CONTAINER ID:容器的id号,随机生成,我们可以对他进行docker stop +id号、docker start +id号,或者docker rm+id号(删除该容器)
IMAGE:我们利用到的镜像文件。
CMMAND:容器启动时执行的命令,有Dockerfile文件指定,后面提到!
PORTS:容器的一些端口信息。
NAMES:注意到,在启动node时我们没有指定--name属性,所以他随机命名了sleepy_bhabha,而启动hub我们指定了--name属性,hub容器的name为我们指定的selenium-hub
由于我们是在后台启动这2个镜像文件的,我们想要看容器启动的log怎么办,以selenium_hub为例子,我们输入docker logs selenium_hub有如下信息:
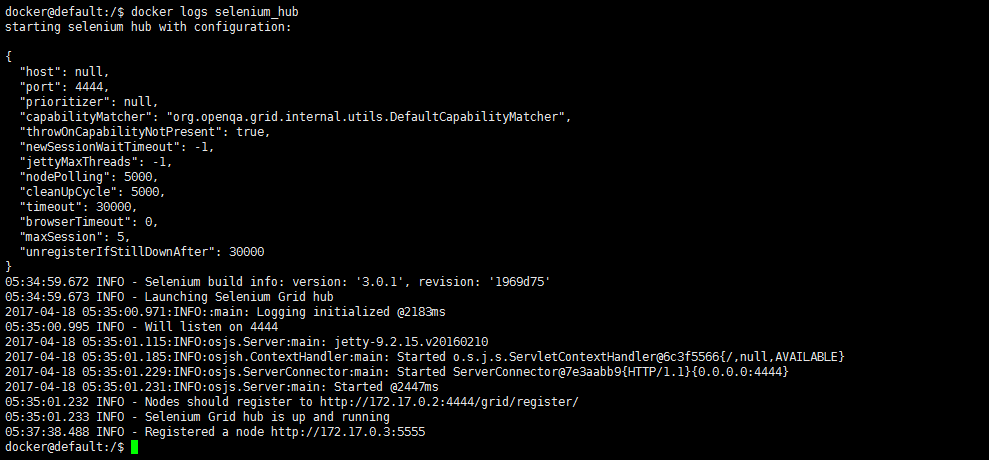
这些信息与我们在本地PC机上使用selenium-server-standalone-×××.jar无异。同理我们可以用docker logs sleepy_bhabha查看node的启动信息。
做完这一切我们在浏览器中输入http://192.168.99.100:5555/grid/console,有如下信息:
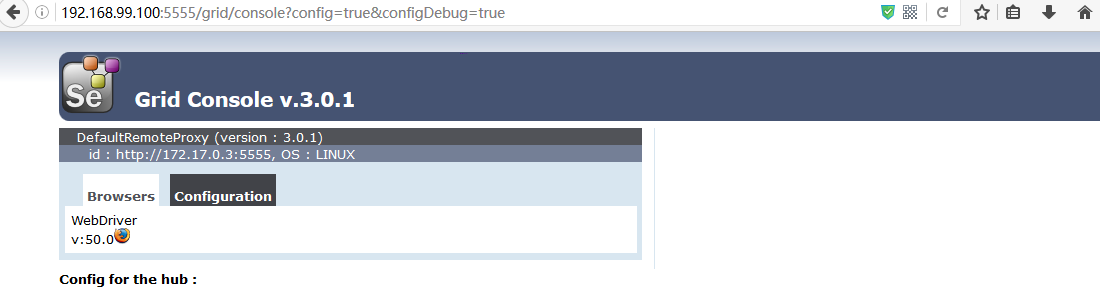
可以看出来,我们的hub中有个新注册的装有firefox浏览器且版本号为50.0的node节点,我们本地写个简单的脚本来测试下这个简单的grid布局代码如下:
#coding=utf-8
from selenium import webdriver
firefox_capabilities ={
"browserName": "firefox",
"version": "50.0",#注意版本号一定要写对
"platform": "ANY",
"javascriptEnabled": True,
"marionette": True,
}
browser=webdriver.Remote("http://192.168.99.100:5555/wd/hub",desired_capabilities=firefox_capabilities)#注意端口号5555是我们上文中映射的宿主机端口号
browser.get("http://www.baidu.com")
browser.get_screenshot_as_file("D:/baidu.png")
browser.close()
代码比较简单,是打开node端的firefox浏览器,输入百度后截图,一切看起来都是那么顺利,但是细心的同事可能发现至少有以前2个问题:
第一、我们对百度的截图中文是乱码的,这个不能忍啊!!!
第二、我们再次在IDE运行下这个脚本,发现一直处于阻塞状态也不报错,得不到hub远程的执行信息~~
对于问题一,因为我们要涉及到关于docker的镜像制作等操作我们放在后面介绍,先来看看第二个问题,为什么我们再次运行这个脚本无法正常执行?
首先,这是和docker无关的,你在真实的PC机上也是同样的结果!既然和docker无关那是selenium-server-standalone-3.3.1.jar这个包的bug了?答案是:也不是!!那到底是什么我们来看看是什么原因。我们打开hub的log(docker logs selenium_hub)。截图如下:

看出来,第一次我们得到了一个包含有Capabilties请求的request后成功的建立了一个session,这个对应于我们第一次在IDE运行上文的脚本;我们第二次再次运行这个脚本,虽然hub得到了这个请求,但是没有成功的建立了一个新的session。那么问题可能出在node端它不容许建立新的session,所以我们一直处于阻塞状态(阻塞的时间由node的启动参数newSessionWaitTimeout决定),除非我们的第一个session被人为的或者由于超时被自动切断后,才能重新建立!
问题知道了,我们如何改进呢?对的是改变node的启动参数。我们seleniu/node镜像默认的关键参数如下:
"capabilities": [
{
"maxInstances": $NODE_MAX_INSTANCES,#大的浏览器实例
......
}
"maxSession": $NODE_MAX_SESSION #大的Session数目


