
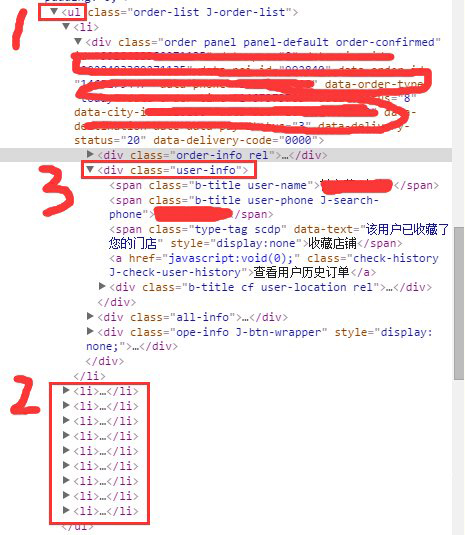
简单说是:用<ul>表示该页的所有订单,<ul>下面的每一个<li>表示一个具体订单,<li>下面的类型为user-info的<div>表示该订单的用户信息,<div>下面是姓名电话等信息。
因此定位过程如下:先用find_elements方法找到<ul>下面的所有<li>;然后遍历每一个<li>,定位用户信息;后再从用户信息中定位姓名电话等。这里用到了层级定位。
1 # 抓取当前页面的所有订单,并调用saveOrderIntoDict将每个订单信息都存入self.orderDict
2 def searchOrderListInCurrentPage(self):
3 # 这里采用CSS定位,但是使用了find_elements,一次定位所有的订单
4 orders = self.driver.find_elements_by_css_selector('ul.order-list.J-order-list > li')
5
6 # 遍历每一个订单,提取其中的用户信息,这里用到了层级定位
7 for one in orders:
8 # 先定位用户信息
9 uesrinfo = one.find_element_by_css_selector('div.user-info')
10 # 再定位具体每项信息
11 name = uesrinfo.find_element_by_css_selector('span.b-title.user-name').text
12 # 有的用户没有写名字
13 if name == '':
14 name = u'无名氏'
15 tel = uesrinfo.find_element_by_css_selector('span.b-title.user-phone.J-search-phone').text
16 address = uesrinfo.find_element_by_css_selector('div > span.fl.J-search-address').text
17 # 信息存入self.orderDict
18 self.saveOrderIntoDict(tel, name, address)
19 return
8、判断是否还有下一页订单
这里使用页面低端的翻页符号来定位,如下图所示。
实现思路可参考 使用selenium实现简单网络爬虫抓取MM图片 ,检查是否到达页面底部的方法:
1 # 判断是否还有下一页
2 # 通过符号>>的上级标签<li>的class属性来判断,当还存在下一页(>>可点击)时,<li>的class属性值为空;当不存在下一页时,<li>的class属性值为disabled
3 # 因此,当我们找到符号>>及其父元素<li class="disabled">时,即可认为不存在下一页,否则存在下一页
4 def hasNextPage(self):
5 try:
6 # 注意这里的选择器一定要包含a[aria-label="Next"],不能只用li.disabled,因为上一页的符号也可能存在li.disabled,必须使用父子元素同时定位
7 self.driver.find_element_by_css_selector('ul.J-pagination.pagination.pagination-md.pull-right > li.disabled > a[aria-label="Next"]')
8 # 如果没抛出异常,说明找到了元素<li class="disabled">和子元素<a aria-label="Next">,没有下一页了
9 return False
10 except NoSuchElementException as e:
11 # 抛出异常说明还存在下一页
12 return True
9、切换到下一页订单
切换很简单,直接定位翻页符号点击即可:
1 # 切换到下一页
2 # 这个比较简单,直接采用类似上面的定位器即可
3 def enterNextPage(self):
4 self.driver.find_element_by_css_selector('ul.J-pagination.pagination.pagination-md.pull-right a[aria-label="Next"] > span').click()
5 return
10、抓取设置日期范围内的所有订单
上面的方法都是些内部实现,无需直接调用,而该方法是供我们直接调用的,这里只是对上面那些方法的组合以及简单处理:
1 # 抓取设定日期范围内的所有订单,抓取订单时直接调用该接口即可
2 def getAllOrders(self, startdate, enddate):
3 # 设置订单的时间范围
4 self.setDate(startdate, enddate)
5
6 # 登录
7 self.login()
8
9 # 切换到历史订单页面
10 self.switchToHistoryOrder()
11
12 # 遍历处理dateList中的所有日期对
13 for date in self.dateList:
14 # 选择date所标示的时间范围
15 self.selectDate(startDate=date[0], endDate=date[1])
16
17 # 依次处理筛选出来的每一页订单
18 while True:
19 # 处理当前页面的订单
20 self.searchOrderListInCurrentPage()
21 # 是否还有下一页
22 if self.hasNextPage():
23 self.enterNextPage()
24 else:
25 break
26
27 # 退出
28 self.logout()
29 return
11、筛选出点餐次数TOP N的顾客
调用第10步的方法后,所有的订单信息都在self.orderDict中了,这里只需将dict转换为list,然后按照cnt降序排序,再输出前10的信息即可。
1 # 筛选出点餐次数排名前N的顾客
2 def getTopN(self, n=10):
3 # 先将orderDict转换为list
4 # {'tel': ['name', 'address', cnt]} -> [('name', 'tel', 'address', cnt)]
5 orderList = [(v[0], k, v[1], v[2]) for (k, v) in self.orderDict.iteritems()]
6
7 # 按照list中每个元素的cnt排序
8 orderList.sort(key=lambda x: x[3], reverse=True)
9
10 # 输出TOP N
11 num = len(orderList)
12 if num < n:
13 n = num
14 for i in range(n):
15 print orderList[i][0]
16 print orderList[i][1]
17 print orderList[i][2]
18 print orderList[i][3]
现在测试一下整个代码:
1 if __name__ == '__main__':
2 order = Order('url', 'username', 'password')
3 # 抓取制定时间范围内的所有订单
4 order.getAllOrders('2016-05-23', '2016-05-25')
5 # 输出TOPN
6 order.getTopN(n=10)
输出形式如下:
1 姓名1
2 13512345678
3 地址1
4 6
5 姓名2
6 13612345678
7 地址2
8 3
9 姓名3
10 13712345678
11 地址3
12 1


