
原因说明
在python中提到unicode,一般指的是unicode对象,例如'哈哈'的unicode对象为 u'u54c8u54c8'
而str,是一个字节数组,这个字节数组表示的是对unicode对象编码(可以是utf-8、gbk、cp936、GB2312)后的存储的格式。这里它仅仅是一个字节流,没有其它的含义,如果想使这个字节流显示的内容有意义,必须用正确的编码格式,解码显示。
在上述脚本运行中,使用type(data)打印在decode前后的data的数据格式,如下:
<type 'str'>
<type 'unicode'>
可以看出,内置的open()方法打开文件时,read()读取的是str格式的:
· Read()读取时,如果参数是str(且内容中含有中文),读取后需要使用正确的编码格式进行decode(),转为unicode字符后,才可以正确显示。
· write()写入时,如果参数是unicode,则需要使用你希望写入的编码进行encode(),如果是其他编码格式的str,则需要先用该str的编码进行decode(),转成unicode后再使用写入的编码进行encode()。
方法二(推荐)
在文件打开时直接指定使用gb18030格式读取后,即可直接操作,另外,该方法对中文txt和英文txt的处理均适用
#coding:utf-8
import codecs
def str_reader_txt(address):
fp=codecs.open(address,'r',"gb18030")
#fp=open(address,'r')
users=[]
pwds=[]
lines=fp.readlines()
for data in lines:
name,pwd=data.split(',')
name=name.strip('
')
pwd=pwd.strip('
')
users.append(name)
pwds.append(pwd)
print "user:%s(len(%d))" %(name,len(name))
print "pwd:%s(len(%d))" %(pwd,len(pwd))
return users,pwds
fp.close()
备注:Codecs.getreader也可以达到同样的效果,如下:
#coding:utf-8
import codecs
def str_reader_txt_csv(address):
f=file(address,'rb')
users=[]
pwds=[]
csv=codecs.getreader('gb18030')(f) #Codecs.getreaderf方法
for data in csv:
name,pwd=data.split(',')
name=name.strip('
')
pwd=pwd.strip('
')
users.append(name)
pwds.append(pwd)
return users,pwds
f.close()
原因说明
模块codecs提供了一个open()方法,可以指定一个编码打开文件,使用这个方法打开的文件读取返回的将是unicode。
写入时,如果参数是unicode,则使用open()时指定的编码进行编码后写入;
如果是str,则先根据源代码文件声明的字符编码,解码成unicode后再进行前述操作。对内置的open()来说,这个方法比较不容易在编码上出现问题,推荐使用
为何使用gb18030的编码格式
下面是通过对比测试的结果,可以看出使用gb18030和UTF-8操作的结果:
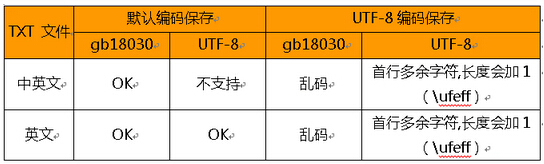
在windows平台下,默认的文档保存方式为ANSI,在简体中文系统下,ANSI 编码代表 GB2312 编码。
在txt保存时,修改保存格式为UTF-8时,可以使用UTF-8编码打开,但是其字符长度有差异,其原因如下:
需要一提的是BOM(Byte Order Mark)。我们在储存文件时,文件使用的编码并没有保存,打开时则需要我们记住原先保存时使用的编码并使用这个编码打开,这样一来产生了许多麻烦。
那记事本打开文件时并没有让选编码?不妨先打开记事本再使用文件 -> 打开一个保存为UTF-8编码格式的txt文档看看
UTF引入了BOM来表示自身编码,如果一开始读入的几个字节是其中之一,则代表接下来要读取的文字使用的编码是相应的编码:
BOM_UTF8 'xefxbbxbf'
BOM_UTF16_LE 'xffxfe'
BOM_UTF16_BE 'xfexff'
那针对UTF-8格式文件存在BOM的情况下,如何获取内容呢?Codec中有个方法codecs.BOM_UTF8可以去参考一下,此处不详细解释
GB2312、GBK、GB18030的区别及联系
这里给出参考链接,http://www.zhihu.com/question/19677619
该文章描述的比较全面清晰,总结一下是:
· GBK完全兼容GB2312
· GB 18030完全兼容GB 2312,基本兼容GBK,支持GB 13000及Unicode的全部统一汉字,共收录汉字70244个。
GB 18030,全称:标准GB 18030-2005《信息技术中文编码字符集》,是中华人民共和国现时新的内码字集,是GB 18030-2000《信息技术信息交换用汉字编码字符集基本集的扩充》的修订版。
中文处理流程总结
处理中文数据时好采用如下方式:
1. Decode early(尽早decode, 将文件中的内容转化成unicode再进行下一步处理)
2. Unicode everywhere (程序内部处理都用unicode)
3. Encode late (后encode回所需的encoding, 例如把终结果写进结果文件)
有几点要说明一下:
* 所谓“正确的”编码,指得是指定编码和字符串本身的编码必须一致。这个其实并不那么容易判断,一般来说,我们直接输入的简体中文字符,有两种可能的编码:GB2312(GBK、GB18030)、以及UTF-8
* GB2312、GBK、GB18030本质上是同一种编码标准。只是在前者基础上扩充了字符数量
* UTF-8和GB编码不兼容
*第二步,将str转化为unicode对象时,可以使用下列两个方法:都是将gb2312编码的str转为unicode编码
· unicode(str,'gb2312')
· str.decode('gb2312')
*另外,在定义字符串时,出现中文,都使用str=u '汉字' 来定义。

