◆ 测试逐步进行,数据增加到39个时进行预测,如图4
选择数据个数39是因为这是Logistic模型拐点的位置。经过计算,45个数据时,样本数据累积值是763,之前计算出的K值再次证明不符合趋势。从图4中可以看出,Gompertz模型预测出预测值为1074.0,Logistic模型预测出的K值为707.9,这意味着样本的趋近值为1074.0或707.9,即到100个数据时,应当发现1074.0或707.9个缺陷。这时的Gompertz模型和Logistic模型差异较大,从各个拟合度指标来看,依然是Gompertz模型更好。

图4 39个样本数据时的预测图
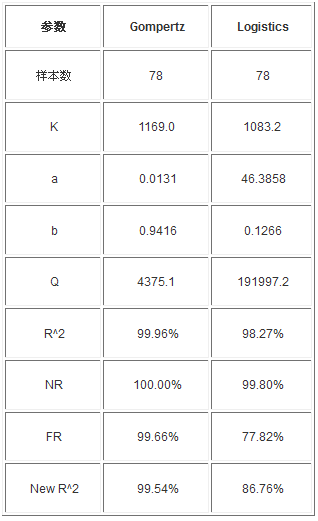
图5 全部样本数据计算得到的预测图
◆ 测试逐步进行,数据增加到78、也是全部的样本数据,如图5
经过计算,全部样本数据的累积值是1123,之前测试出的K值(1167.1或976.3)中的1167.1可能符合趋势,但仍然需要进行预测验证。从图5中可以看出,Gompertz模型预测出预测值为1169,Logistic模型预测出的K值为1083.2,由于Logistic模型预测出的K值在多次实验中都小于样本累积值,可以判断出Logistic模型并不符合给定样本的趋势,这也意味着样本的趋近值为Gompertz模型预测得到的K值,即1169,即到100个数据时应当发现1169个缺陷。
由此可见,K值的变化趋势经历了不断增长的一个过程,从不断增加,到趋于稳定,如图6,此时的K的变化情况近似于指数曲线。
图6 渐近值K的变化趋势

