下面以项目数据为例进行K值分析。
● K值并不是不变的,而是随着样本数据的增多在不断改变。接下来,我们会以实际项目数据为例来分析K值的变化情况。原始数据个数是78,测试结果是得到100个预测点。本实验只考虑Gompertz模型和Logistic模型。
◆ 测试开始初期,仅有9个数据时进行预测,如图2
选择9个数据是因为三和法对数据的基本要求即为“样本数据个数大于9个”,所以我们选择起点:9个数据点作为渐近值分析的起点。
从图2中可以看出,9个数据时,样本数据的累积值为100,预测值(即K)为187.0和103.5,这意味着样本的趋近值为187.0和103.5,即到100个数据时,应当发现187.0或103.5个缺陷。Gompertz模型和Logistic模型都较为符合样本趋势,Gompertz模型稍好。

图2 9个样本数据时的预测
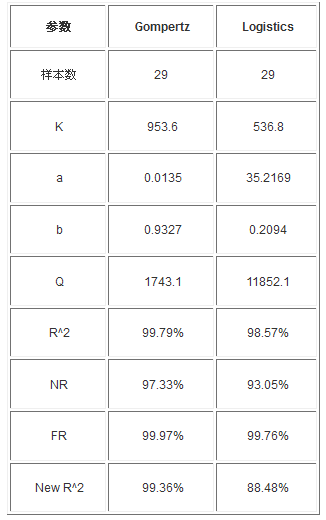
图3 29个样本数据时的预测图
◆ 测试逐步进行,Gompertz模型数据增加到29个时进行预测,如图3
选择数据个数29的原因:根据实验得出,Gompertz模型的拐点出现在大约在37%(1/e)的位置。这里我们使用的历史数据个数是78个,因此得到拐点的位置大概在第29个。
从图3中可以看出,29个数据时,样本数据累积值是555,可见之前预测得到的K(187.0和103.5)都不再符合趋势。此时,Gompertz模型预测出的K值为953.6,Logistic模型预测出的K值为536.8,这意味着样本的趋近值为953.6或536.8,即到100个数据时,应当发现953.6或536.8个缺陷。这时的Gompertz模型和Logistic模型差异较大,从各个拟合度指标及样本数据累积值来看,Gompertz模型更好。但是,实验中,Logistic模型的拐点并不在37%处,而是在50%处。

