
高效重构 C++ 代码(下)
作者:魔术大师 发布时间:[ 2016/9/29 16:25:19 ] 推荐标签:测试开发技术 C++
· makefile采用自底向上组织,保证每个源代码文件单独可编译,每个模块单独可编译. 终产品版本的构建调用每个模块的makefile生成编译中间产物后进行链接. 不要采用自顶向下传递make参数的makefile工程管理模式,否则每次编译任何一个文件或者模块都要全编译所有代码.
· 尽可能使用并行编译. 在Visual Studio下可以使用IncrediBuild分布式编译工具. 对于make使用-j选项,并且可以使用distcc来进行分布式编译.另外可以使用ccache来做缓存加速编译。
· 将测试工程的编译构建和真实产品版本的构建分离,测试工程的编译构建可以采用更好的工具:例如cmake,rake等.
· 保证增量编译可用,并且是可靠的.
很多项目虽然有增量编译,但是都不够可靠,尤其是当有头文件删除的时候! 另外每次无论是否有依赖变化,makefile都要重新生成加载.d文件,效率也很低下. 所以大多数时候增量编译功能是关闭的!
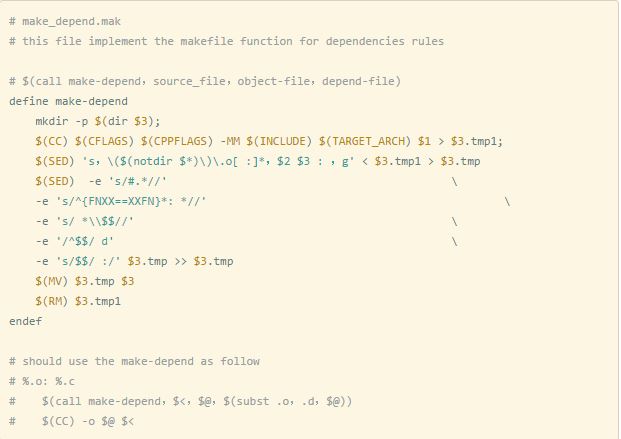
《GNU Make项目管理》一书中提供了很多大型工程中make组织的实践,其中有一段对增量编译可靠高效的makefile片段,我将其提炼成了一段make函数,见下面,大家可以使用.
总结
我过去几年的工作主要在大型电信系统的软件重构, 这篇文章基本上是自己工作实践的一些心得,包括对《重构》一书的一些精炼和总结. 当然关于重构精华的部分还是在原书的每一处细节中. 励志学好重构的同学对于《重构》一书好能够反复阅读实践.
对于再大型的软件重构,无论你的目标架构多么漂亮,终还必须是一行一行的代码修改。如何安全可靠并且高效地修改代码,必然是落地的基本技能!
对于日常开发也是如此, 保持代码符合简单设计是一项日常行为,重构是达成它的方式. 对重构的使用应该融入到代码开发的每时每刻,到后不必强行区分是在开发还是重构,像《重构》的序言中所说”变得像空气和水一样普通”. 希望每个学习重构的同学都能体会到这种感觉!
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系SPASVO小编(021-61079698-8054),我们将立即处理,马上删除。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11热门文章
常见的移动App Bug??崩溃的测试用例设计如何用Jmeter做压力测试QC使用说明APP压力测试入门教程移动app测试中的主要问题jenkins+testng+ant+webdriver持续集成测试使用JMeter进行HTTP负载测试Selenium 2.0 WebDriver 使用指南

 sales@spasvo.com
sales@spasvo.com