
Nginx中Map模块的使用及性能测试
作者:网络转载 发布时间:[ 2016/9/22 15:54:36 ] 推荐标签:性能测试 Nginx
压测机器
临时租了两台阿里云服务器(因为是临时的,所以我也不在意在后文暴露ip了)。
配置都是:1核,2048M内存,40G硬盘。
一台用作nginx和helloworld程序,一台专门做abtest。
注:abtest也在阿里云执行只要是为了在一个数据中心降低网络延迟。后发现效果真不错,rps从100多直接飙升到2700多。
helloworld
采用了nodejs的helloworld:
varhttp =require('http');
vari =0;
http.createServer(function(req, res){
console.log(i++);
res.writeHead(200, {'Content-Type':'text/plain'});
res.end('Hello World
');
}).listen(1337,"0.0.0.0");
console.log('Server running at http://0.0.0.0:1337/');
url-mapping
生成urlmapping写了一个python脚本:
importhashlib
m2 = hashlib.md5()
current = "hello world"
f = open('./url.map','w')
foriinrange(100):
m2.update(current)
current = m2.hexdigest()
f.write('~^/hello/world/'+ current +'\b(?[^/]*)*/?$ /;
')
f.close()
nginx配置:
server {
listen 80;
server_name 120.26.138.197;
location ^~ /{
if ($new) {
proxy_pass http://120.26.138.197:1337$new;
break;
}
return 404;
}
}
abtest
rps测试(request per second)
并发压测使用100000次请求,并发100个用户的方式:
# 不走nginx
ab -n100000 -c100 120.26.138.197:1337/
# 走nginx
ab -n100000 -c100 120.26.138.197/hello/world/5eb63bbbe01eeed093cb22bb8f5acdc3/
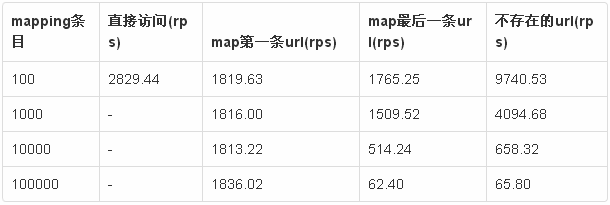
跟预想的一样,mapping的条目确实会对请求效率产生影响。而且几万条的映射在较高并发的情况下已经到了勉强能用的临界了。还好以后mapping的条目不会再增加了,并且论坛的并发很难到100的量级。
tpr测试(time per request)
因为考虑到服务器比较稳定,减少压测总数。同时把并发用户减为1个。
# 不走nginx
ab -n1000 -c1 120.26.138.197:1337/
# 走nginx
ab -n1000 -c1 120.26.138.197/hello/world/5eb63bbbe01eeed093cb22bb8f5acdc3/
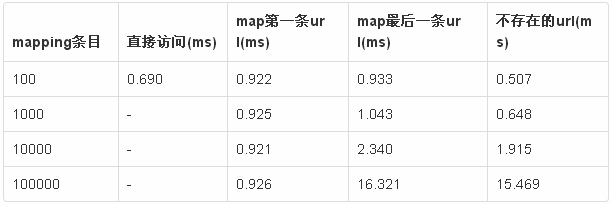
在并发不是很高的时候mapping的条目可以更多。100000个条目大概只会影响整个请求15ms左右,可以忽略不计。如果说150ms的延迟是可以接受的,那么在一个并发不是很高的情况下,mapping多可以有100w条,还是很多的
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com