
测试来带个节奏之 API 测试工具篇
作者:大大灰灰狼 发布时间:[ 2016/8/23 10:47:33 ] 推荐标签:软件测试 API测试工具
测试结果如下:
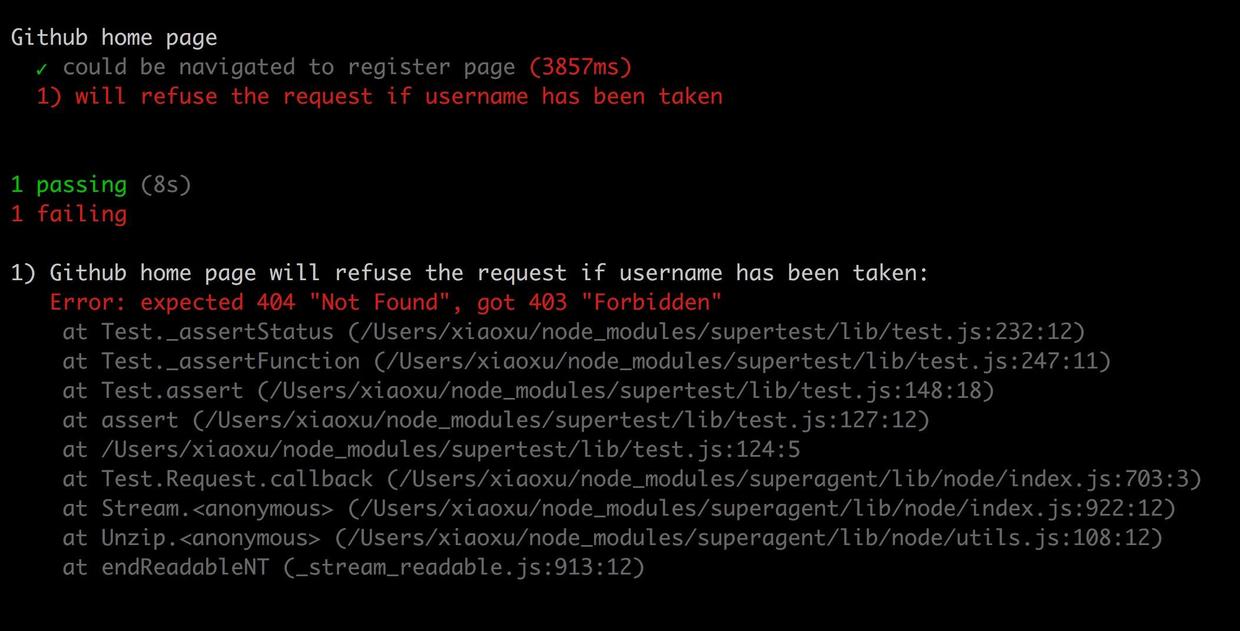
更新后一个用例中的.expect(404)为.expect(403),测试通过。
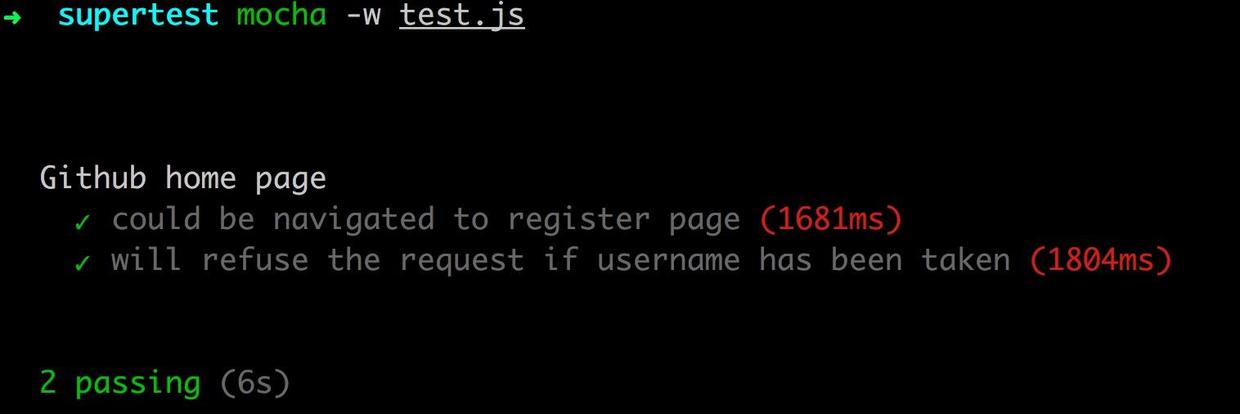
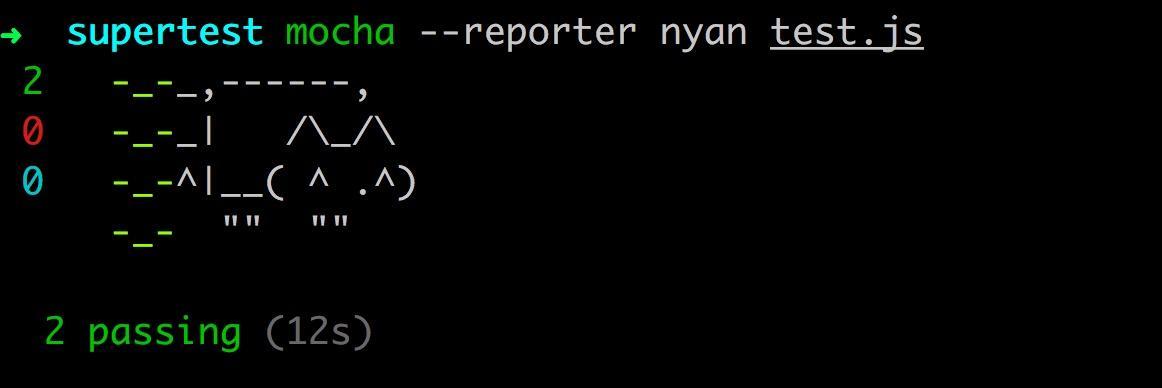
现在不管是测试代码的可读性还是测试报告的可读性,都比之前强多了。而且还可以使用--reporter参数让测试报告变成各种形状,比如
查漏补缺:总算是解决了代码可读性和测试报告的问题。再回过头来看看整个demo,突然发现调研了这么半天,竟然忽略了在很多业务场景中,调用API需要验证用户是否登录的问题。换句话说,需要在不同的http请求中保持cookie。
幸好supertest提供了这个解决方案,使用supertest的agent功能来解决这个问题。
var request = require('superset')
describe('测试cookie', function(){
var agent = request.agent('待测server');
it('should save cookies', function(done){
agent
.get('/')
.expect('set-cookie', 'cookie=hey; Path=/', done);
})
it('should send cookies', function(done){
agent
.get('/return')
.expect('hey', done);
})
})
可以看到第一个用例是测试cookie=hey,而到了第二个测试里面,由于被测实例由单纯的"request"变成了"request.agent()",所以cookie “hey”被agent带入到了第二个用例中,当访问"/return"的时候不用再重新set cookies了。
另外我们也可以通过在每次请求前去set cookie的方法达到同样的效果。
.set('Cookie', 'a cookie string')
后如果是要测试授权资源的话,superagent也提供了.auth()方法去获取授权。
request .get('http://local')
.auth('tobi', 'learnboost') .
end(callback);
现在看上去调研工作算是差不多了,能够满足大部分的测试场景。接下来只需要再设计下测试代码结构,抽象下公共组件,做下参数化,分离下测试数据搞定了。可是细想下,如果需要写了一大堆测试的话,难道要挨个去执行mocha xxx脚本的命令来跑测试?
还好项组目已经在用grunt构建工具。谷歌一下发现有一个grunt插件“grunt-mocha-test”貌似挺不错的。按照它的说明文档,只需要在grunt配置文件里面加上一段
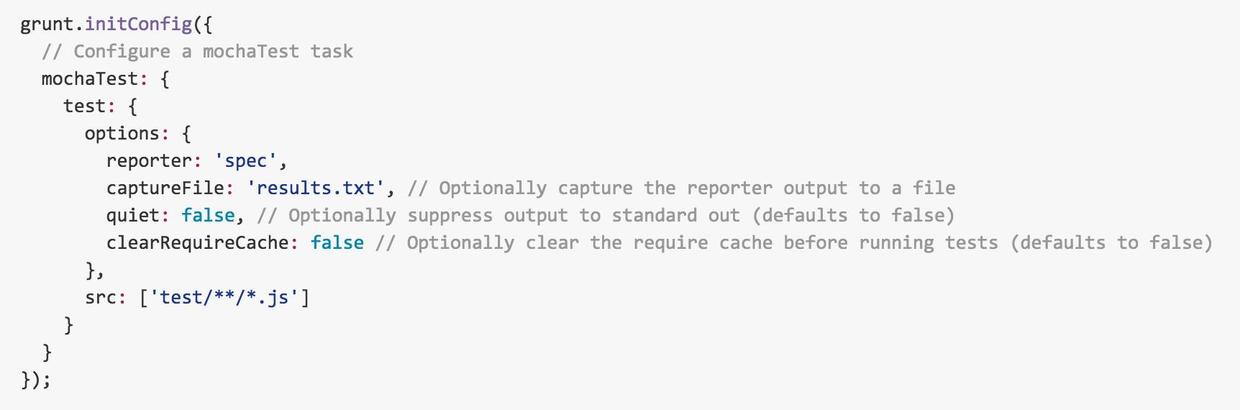
grunt-mocha-test配置
其中reporter是制定报告的格式, src是需要执行的脚本的路径,*.js指定执行全部js格式的文件。
后再注册一个grunt命令,比如:
grunt.registerTask('apitest', 'mochaTest');
能简单的在命令行中使用
grunt apitest
来执行所有的测试文件了。这样也可以方便的在Jenkins中配置一个新的测试任务,加入持续集成。
至此,工具选型全部完成,核心是supertest,包装是mocha,执行用grunt,收工。
总结一下
· 总结一下,在工具选型的时候,建议考虑这些方面:
· 结合项目技术栈使用
· 新工具学习成本、维护成本、可扩展性
· 是否可以简单实现代码满足所有业务场景,比如非REST风格的API,或者一些特殊场景
· 代码易读,测试报告可视化
· 脚本执行简单
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com