
如何设计OpenStack测试用例?
作者:网络转载 发布时间:[ 2016/8/19 11:04:07 ] 推荐标签:测试用例 OpenStack
4.场景设计法
现在的软件几乎都是用事件触发来控制流程的,事件触发时的情景便形成了场景,而同一事件不同的触发顺序和处理结果形成事件流。这种在软件设计方面的思想也可以引入到软件测试中,有利于设计测试用例,同时使测试用例更容易理解和执行。

5.错误猜测法
错误猜测法是根据经验和直觉推测程序中所有可能存在的各种错误,从而有针对性地设计测试用例的方法。
例如,在云硬盘的挂载使用中,为了验证云硬盘的挂载-卸载-重新挂载对数据完整性的保护这一场景测试。因而,可以将一个数据卷挂载到VM上,写入文件,然后umount、卸载,重新挂载给另一个VM来验证软件是否存在缺陷等。
6.正交表
由于因果图/判定表设计测试用例的固有弊端;以及为了解决穷举测试的弊端,因此需要使用正交表设计方法:即从大量的测试数据中挑选出适量的、有代表性的测试数据,从而合理地做出测试设计。各列中出现大数字相同的正交表称为相同水平正交表。如L4(23)、L8(27)、L12(211)等各列中大数字为2,称为两水平正交表。此设计方法适用于各种组合场景的测试,比如“更多搜索”。
正交表的构成
1.行数(Runs):正交表中的行的个数,即试验的次数,也是我们通过正交实验法设计的测试用例的个数。
2.因素数(Factors) :正交表中列的个数,即我们要测试的功能点。
3.水平数(Levels):任何单个因素能够取得的值的大个数。即测试功能点的输入条件个数。
正交表的两个特点:
正交表必须满足这两个特点,有一条不满足,不是正交表。
1)每列中不同数字出现的次数相等。例如,在两水平正交表中,任何一列都有数码“0”与“1”,且任何一列中它们出现的次数是相等的。这一特点表明每个因素的每个水平与其它因素的每个水平参与试验的几率是完全相同的,从而保证了在各个水平中大限度地排除了其它因素水平的干扰,能有效地比较试验结果并找出优的试验条件。
2)在任意两列其横向组成的数字对中,每种数字对出现的次数相等。例如,在两水平正交表中,任何两列(同一横行内)有序对子共有4种:(1,1)、(1,2)、(2,1)、(2,2)。每种对数出现次数相等。在三水平情况下,任何两列(同一横行内)有序对共有9种,1.1、1.2、1.3、2.1、2.2、2.3、3.1、3.2、3.3,且每对出现数也均相等。这个特点保证了试验点均匀地分散在因素与水平的完全组合之中,因此具有很强的代表性。
以上两点充分的体现了正交表的两大优越性,即“均匀分散性,整齐可比性”。通俗的说,每个因素的每个水平与另一个因素的水平各碰一次,这是正交性。
如何选择正交表
- 考虑因素(变量)的个数;
- 考虑因素水平(变量的取值)的个数;
- 考虑正交表的行数;
- 取行数少的一个;
设计测试用例时的三种情况
- 因素数(变量)、水平数(变量值)相符;
- 因素数不相同;
- 水平数不相同;
正交表的形式:

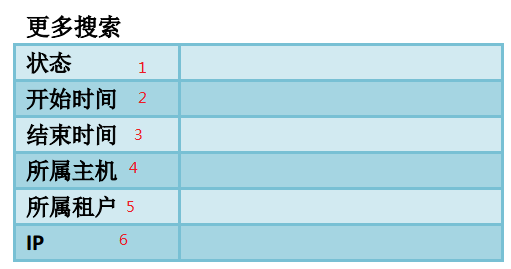
这是云平台中的一个“更多搜索”模块(由于某些原因,只能贴设计表)。我们可以看到要测试的控件有6个:状态、开始时间、结束时间、所属主机、所属租户、IP,也是说要考虑的因素有6个;而每个因素的选项(水平数)有2个:填与不填。
选择正交表时分析一下:
1、表中的因素数>=6;
2、表中至少有6个因素数的水平数>=2;
3、行数取少的一个。
从正交表公式中开始查找,结果为:
L4(26):表示需做>=4次实验,可测试6个因素,每个因素均为2水平。
变量映射:
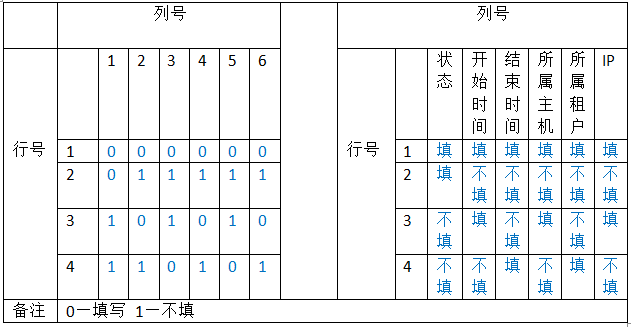
测试用例如下:
1:填写状态、填写开始时间、填写结束时间、填写所属主机、填写所属租户、填写IP
2:填写状态、不填开始时间、不填结束时间、不填所属主机、不填所属租户、不填IP
3:不填状态、填写开始时间、不填结束时间、填写所属主机、不填所属租户、填写IP
4:不填状态、不填开始时间、填写结束时间、不填所属主机、填写所属租户、不填IP
增补测试用例:
5:不填状态、不填开始时间、不填结束时间、不填所属主机、不填所属租户、不填IP
测试用例减少数:64-5=59
7.基于需求的测试方法
即根据客户需求、业务和逻辑设计需求、场景和功能需求(比如平台可用性测试、故障HA测试、后端/前端性能测试)等进行相关的测试。要求测试人员全面清晰地掌握用户需求;明确测试的目标和任务;设计基于需求的测试用例;建立测试报告通报制度(建立测试报告审批通报制度对于提升软件质量具有明显作用。作为一名的测试工程师,应将已经发现的缺陷或错误进行分析汇总,用统计数字、图表等方式说明缺陷或错误的根源,及时将测试工作报告提交上级主管领导审议,并通知研发设计人员,使设计人员做到对缺陷心中有数、控制有道,以防患于未然)
基于需求的测试方法五项佳实践
1)转变“编码后进行测试”的传统观念。在软件编码开始之前的设计阶段根据需求文档和设计文档开发出90%以上的测试用例,尽早发现和排除绝大部分的缺陷。即转入测试驱动开发的佳实践(TDD)。
2)根据各项应用功能的优先级、重要性制订不同等级的测试方案、测试用例。重要模块和次要模块投入的测试资源。
3)尽早测试,频繁测试。测试进行得越早,缺陷发现越早,修复缺陷的代价越小;测试进行得越晚,缺陷发现越迟,修复缺陷的代价越大。
4)摒弃“经验至上”的想法。设计系统、严谨、合理的测试用例才能使测试达到实效。
5)加强对测试过程的监控跟踪。当用户需求发生变更时,软件需求文档和设计文档都随之发生变更,相应测试用例也应发生变更。保证测试用例和用户需求的双向统一。
8.综合策略
使用各种测试方法的综合策略:
1)在任何情况下都必须使用边界值分析方法,经验表明用这种方法设计出测试用例发现程序错误的能力强。
2)必要时用等价类划分方法补充一些测试用例。
3)用错误猜测法再追加一些测试用例。
4)对照程序逻辑,检查已设计出的测试用例的逻辑覆盖程度,如果没有达到,应当再补充足够的测试用例。
5)如果程序的功能中含有输入条件的组合情况,则选用因果图法或正交表。
界面测试总结(如何针对文本框进行测试)
a、输入正常的字母或数字;
b、输入已存在的名称;
c、输入超长字符;例如在“名称”框中输入超过允许边界个数的字符,检查程序能否正确处理;
d、输入默认值,空白,空格,特殊符号;
e、若只允许输入字母,尝试输入数字;反之,尝试输入字母;
f、利用复制,粘贴等操作强制输入程序不允许的输入数据;
g、输入特殊字符集;
h、输入超过文本框长度的字符或文本,检查所输入的内容是否正常显示;
i、输入不符合格式的数据,检查程序是否正常校验(判断);
例如,程序要求输入年月日格式为yy/mm/dd,实际输入yyyy/mm/dd,则程序应该给出错误提示。
为测试用例设置优先级需要采取两个原则:
1)将使用频率比较高的测试场景设置为高优先级的;
2)根据测试场景失败后对系统、用户的影响大小设置其优先级;
这样将两者相加得到了每个测试用例的优先级了。根据优先级的排序可以更有针对性的进行测试用例的详细设计了。此时,还需要为每个测试用例设计相关的测试数据。对测试数据的设置有两个要求:
1)正常数据
2)非法数据
应当优先考虑正常数据,而且正常数据的设计必须是有实际意义的。然后再考虑设计非法数据。这两种数据中都应该包含边界数据,因为边界数据往往是容易出错的地方。
当我们设计完测试数据后,可以开始对测试用例进行详细设计了。在具体的测试步骤中,需要包含的主要内容是:操作步骤,测试数据以及期望结果。当我们完成了这些工作,一个完整的测试用例写完了。
当然,除了以上讲到的软件测试用例设计方法(黑盒测试)之外,还有诸如包括语句覆盖、判定覆盖(也称为分支覆盖)、条件覆盖、判定/条件覆盖、条件组合覆盖、基本路径分析法等在内的白盒测试方法。这里不一一列举了。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com