
大型网站架构改进历程:存储的瓶颈(上)
作者:网络转载 发布时间:[ 2015/8/6 11:38:15 ] 推荐标签:WEB测试 软件测试
写到这里一个婴儿般的网站这样被我们创造出来了,我们希望网站能健康快速的成长,如果网站真的按我们预期成长了,那么一定会有我们制造的宝宝屋已经满足不了现实的需求,这个时候我们应该如何抉择了?换掉,全部换掉,使用新的架构例如我们以前长提的SOA架构,分布式技术,这个方法不错,但是SOA和分布式技术是很难的,成本是很高的,如果这时候我们通过添加几台服务器能解决问题的话,我们不要去选择什么分布式技术,因为这个成本太高了。上面我讲到几种session共享的方案,这个方案解决了应用的水平扩展问题,那么当我们网站出现瓶颈时候多加几台服务器不行了吗?那么这里有个问题了,当网站成长很快,网站首先碰到的瓶颈到底是哪个方面的问题?
本人是做金融网站的,我们所做的网站有个特点是当用户访问到我们所做的网站时候,目的都很明确是为了付钱,用户到了我们所做的网站时候都希望能快点,再快点完成本网站的操作,很多用户在使用我们做的网站时候不太去关心网站的其他内容,因此我们所做的网站相对于数据库而言是读写比例其实非常的均匀,甚至很多场景写比读要高,这个特点是很多专业服务网站的特点,其实这样的网站和企业开发的特点很类似:业务操作的重要度超过了业务展示的重要度,因此专业性网站吸纳企业系统开发的特点比较多。但是大部分我们日常常用的网站,我们逗留时间很长的网站按数据库角度而言往往是读远远大于写,例如大众点评网站它的读写比率往往是9比1。
12306或许是中国的网站之一,我记得12306早期经常出现一个问题是用户登录老是登不上,甚至在高峰期整个网站挂掉,页面显示503网站拒绝访问的问题,这个现象很好理解是网站并发高了,大量人去登录网站,购票,系统挂掉了,后所有的人都不能使用网站了。当网站出现503拒绝访问时候,那么这个网站出现了致命的问题,解决大用户访问的确是个超级难题,但是当高并发无法避免时候,整个网站都不能使用这个只能说网站设计上发生了致命错误,一个好的网站设计在应对超出自己能力的并发时候我们首先应该是不让他挂掉,因为这种结果是谁都不能使用,我们希望那些在可接受的请求下,让在可接受请求范围内的请求还是可以正常使用,超出的请求可以被拒绝,但是它们不能影响到全网站的稳定性,现在我们看到了12306网站的峰值从未减少过,而且是越变越多,但是12306出现全站挂掉的问题是越来越少了。通过12036网站改变我们更进一步思考下网站的瓶颈问题。
排除一些不可控的因素,网站在高并发下挂掉的原因90%都是因为数据库不堪重负所致,而应用的瓶颈往往只有在解决了存储瓶颈后才会暴露,那么我们要升级网站能力的第一步工作是提升数据库的承载能力,对于读远大于写的网站我们采取的方式是将数据库从读写这个角度拆分,具体操作是将数据库读写分离,如下图所示:
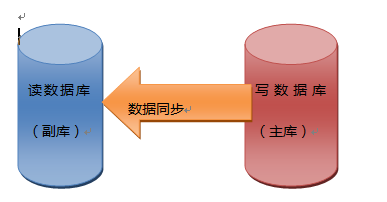
我们这时要设计两个数据库,一个数据库主要负责写操作我们称之为主库,一个数据库专门负责读操作我们称之为副库,副库的数据都是从主库导入的,数据库的读写分离可以有效的保证关键数据的安全性,但是有个缺点是当用户浏览数据时候,读的数据都会有点延时,这种延时比起全站不可用那肯定是可以接受的。不过针对12306的场景,仅仅读写分离还是远远不够的,特别是负责读操作的副库,在高访问下也是很容易达到性能的瓶颈的,那么我们得使用新的解决方案:使用分布式缓存,不过缓存的缺点是不能有效的实时更新,因此我们使用缓存前首先要对读操作的数据进行分类,对于那些经常不发生变化的数据可以事先存放到缓存里,缓存的访问效率很高,这样会让读更加高效,同时也减轻了数据库的访问压力。至于用于写操作的主库,因为大部分网站读写的比例是严重失衡,所以让主库达到瓶颈还是比较难的,不过主库也有一个读的压力是主库和副库的数据同步问题,不过同步时候数据都是批量操作,而不是像请求那样进行少量数据读取操作,读取操作特别多,因此想达到瓶颈还是有一定的难度的。听人说,美国牛逼的facebook对数据的任何操作都是事先合并为批量操作,从而达到减轻数据库压力的目的。
上面的方案我们可以保证在高并发下网站的稳定性,但是针对于读,如果数据量太大了,算网站不挂掉了,用户能很快的在海量数据里检索到所需要的信息又成为了网站的一个瓶颈,如果用户需要很长时间才能获得自己想要的数据,很多用户会失去耐心从而放弃对网站的使用,那么这个问题又该如何解决了?
解决方案是我们经常使用的百度,谷歌哪里得来,对于海量数据的读我们可以采用搜索技术,我们可以将数据库的数据导出到文件里,对文件建立索引,使用倒排索引技术来检索信息,我们看到了百度,谷歌有整个互联网的信息我们任然能很快的检索到数据,搜索技术是解决快速读取数据的一个有效方案,不过这个读取还是和数据库的读取有所区别的,如果用户查询的数据是通过数据库的主键字段,或者是通过很明确的建立了索引的字段来检索,那么数据库的查询效率是很高的,但是使用网站的人跟喜欢使用一些模糊查询来查找自己的信息,那么这个操作在数据库里是个like操作,like操作在数据库里效率是很低的,这个时候使用搜索技术的优势非常明显了,搜索技术非常适合于模糊查询操作。
OK,很晚了,关于存储的问题写在这里,下一篇我将接着这个主题讲解,解决存储问题是很复杂的,下篇我尽量讲仔细点。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com