
如何应用性能测试常用计算公式
作者:网络转载 发布时间:[ 2015/5/27 9:36:10 ] 推荐标签:性能测试
1.问题提出
性能测试中有很多非常重要的概念,如吞吐量、大并发用户数、大在线用户数等。有很多读者也非常关心,如何针对自身的系统确定当前系统,在什么情况下可以满足系统吞吐量、并发用户数等指标要求呢?
2.问题解答
(1)吞吐量计算公式。
吞吐量(Throughput)指的是单位时间内处理的客户端请求数量,直接体现软件系统的性能承载能力。通常情况下,吞吐量用"请求数/s"或者"页面数/s"来衡量。从业务角度来看,吞吐量也可以用"业务数/h"、"业务数/天"、"访问人数/天"、"页面访问量/天"来衡量。从网络角度来看,还可以用"字节数/h"、"字节数/天"等来衡量网络的流量。
吞吐量是大型门户网站以及各种电子商务网站衡量自身负载能力的一个很重要的指标,一般吞吐量越大,系统单位时间内处理的数据越多,系统的负载能力也越强。
吞吐量是衡量服务器承受能力的重要指标。在容量测试中,吞吐量是一个重点关注的指标,因为它能够说明系统的负载能力。而且,在性能调试过程中,吞吐量也具有非常重要的价值,例如,Empirix公司在报告中声称,在他们所发现的性能问题中,有80%是因为吞吐的限制而引起性能问题。
显而易见,吞吐量指标在性能测试中占有着重要地位。那么吞吐量会受到哪些因素影响,该指标和虚拟用户数、用户请求数等指标有何关系呢?吞吐量和很多因素有关,如服务器的硬件配置,网络的拓扑结构,网络传输介质,软件的技术架构等。此外,吞吐量和并发用户数之间存在一定的联系。通常在没有遇到性能瓶颈的时候,吞吐量可以采用下面的公式计算:
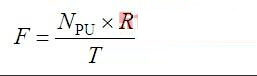
这里,F表示吞吐量; 表示并发虚拟用户个数(Concurrency Virtual User,并发虚拟用户),R表示每个VU发出的请求数量,T表示性能测试所用的时间。但如果遇到了性能瓶颈,此时吞吐量和VU数量之间不再符合给出公式的关系。
(2)并发数量计算公式。
关于并发(Concurrency),简单的描述是指多个同时发生的业务操作。例如,100个用户同时单击登录页面的"登录"按钮操作。通常,应用系统会随着用户同时应用某个具体的模块,而导致资源的争用问题,例如,50个用户同时执行统计分析的操作,由于统计业务涉及很多数据提取以及科学计算问题,所以这个时候很有可能内存和CPU会出现瓶颈。并发性测试描述的是多个客户端同时向服务器发出请求,考察服务器端承受能力的一种性能测试方式。
有很多用户在进行性能测试过程中,对"系统用户数"、"在线用户数"、"并发用户数"的概念不是很清楚,这里我们举一个例子来对这几个概念进行说明。假设有一个综合性的网站,用户只有注册后登录系统才能够享有,新闻、论坛、博客、免费信箱等服务内容。通过数据库统计可以知道,系统的用户数量为4000人,4000即为"系统用户数"。通过操作日志我们可以知道,系统高峰时有500个用户同时在线,关于在线用户有很多第三方提供插件可以进行统计,这里以http://www.51.la为例,这里"在线用户数"即为500。这500个用户的需求肯定是不尽相同的,有的人喜欢看新闻、有的人喜欢写博客、收发邮件等。这里假设这500个用户中有70%在论坛看邮件、帖子、新闻以及他人博客的文章(有一点需要提醒大家的是,"看"这个操作是不会对服务器端造成压力的);有10%在写邮件和发布帖子(用户仅在发送或者提交写的邮件或者发布新贴的时候,才会对系统服务器端造成压力);有10%的用户什么都没有做;有10%的用户不停地从一个页面跳到另一个页面。在这种场景下,通常我们说有10%的用户真正对服务器构成了压力(即10%不停地在网页间跳转的用户),极端情况下可以把写邮件和发布帖子的另外10%的用户加上(此时假设这些用户不间断的发送邮件或发布帖子),也是说此时有20%的用户对服务器造成压力。从上面的例子可以看出,服务器承受的压力不仅取决于业务并发用户数,还取决于用户的业务场景。
那么如何获得在性能测试过程中大家都很关心的并发用户数的数值呢?这里我们给出《软件性能测试过程详解与案例剖析》一书中的一些用于估算并发用户数的公式。

在公式(1)中,C是平均的并发用户数;n是login session的数量;L是login session的平均长度;T指考察的时间段长度。
公式(2)则给出了并发用户数峰值的计算公式,其中,C 指并发用户数的峰值,C是公式(1)中得到的平均的并发用户数。该公式的得出是假设用户的login session产生符合泊松分布而估算得到的。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com