
LoadRunner没有告诉你的
作者:网络转载 发布时间:[ 2015/3/30 16:37:23 ] 推荐标签:性能测试工具 性能测试
理解性能
在这篇短文中,我将尽可能用简洁清晰的文字写下我对“性能”的看法,并澄清几个容易混淆的概念,帮助大家更好的理解“性能”的含义。
如何评价性能的优劣:用户视角vs.系统视角
对于终用户(End-User)来说,评价系统的性能好坏只有一个字——“快”。终用户并不需要关心系统当前的状态——即使系统这时正在处理着成千上万的请求,对于用户来说,由他所发出的这个请求是他需要关心的,系统对用户请求的响应速度决定了用户对系统性能的评价。
而对于系统的运营商和开发商来说,期望的是能够让尽可能多的用户在任意时刻都拥有好的体验,这要确保系统能够在同一时间内处理更多的用户请求。正如在《理发店模型》一文中所描述的:系统的负载(并发用户数)与吞吐量(每秒事务数)、响应时间以及资源利用率(包括软硬件资源)之间存在着一个“此消彼长”的关系。因此,从系统的运营商和开发商的角度来看,所谓的“性能”是一个整体的概念,是系统的负载与吞吐量、可接受的响应时间以及资源利用率之间的平衡。
换句话说,“好的性能”意味着更大的佳并发用户数(The Optimum Number of Concurrent Users)和大并发用户数(The Maximum Number of Concurrent Users)。有关“佳/大并发用户数”的概念请参见《理发店模型》一文。
另外,从系统的视角来看,所需要关注的还包括三个与“性能”有关的属性:可靠性(Reliability),可伸缩性(Scalability)和可恢复性(Recoverability)——我将会在本系列文章的第五篇“无处不在的性能测试”中专门讨论这三个属性的含义和相关的实践经验。
响应时间
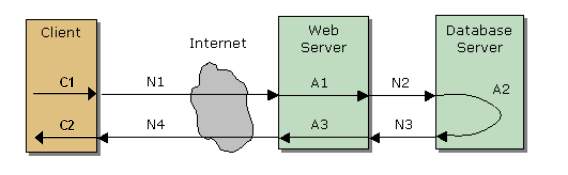
上面这张图引自段念兄的一份讲义,不过我略作了些修改。从图中我们可以清楚的看到一个请求的响应时间是由几部分时间组成的,包括
C1:用户请求发出前在客户端需要完成的预处理所需要的时间;
C2:客户端收到服务器返回的响应后,对数据进行处理并呈现所需要的时间;
A1:Web/App Server对请求进行处理所需要的时间;
A2:DB Server对请求进行处理所需的时间;
A3:Web/App Server对DB Server返回的结果进行处理所需的时间;
N1:请求由客户端发出并达到Web/App Server所需要的时间;
N2:如果需要进行数据库相关的操作,由Web/App Server将请求发送至DB Server所需要的时间;
N3:DB Server完成处理并将结果返回Web/App Server所需的时间;
N4:Web/App Server完成处理并将结果返回给客户端所需的时间;
从用户的角度来看,响应时间=(C1+C2)+(A1+A2+A3)+(N1+N2+N3+N4);但是从系统的角度来看,响应时间只包括(A1+A2+A3)+(N1+N2+N3+N4)。
在理解了响应时间的组成之后,可以帮助我们通过对响应时间的分析来更好的识别和定位系统的性能瓶颈。
吞吐量vs.吞吐量
在不同的测试工具中,对于吞吐量(Throughput)会有不同的解释。例如,在LoadRunner中,这个指标是以字节数为单位来衡量网络吞吐量的,而在JMeter中则是以事务数/秒为单位来衡量系统的响应能力的。不过在大多数英文的性能测试方面的书籍或资料中,吞吐量的定义使用的是后者。
并发用户数≠每秒请求数
这是两个容易让初学者混淆的概念。
简单说,当你在性能测试工具或者脚本中设置了100并发用户数后,并不能期望着一定会有每秒100个请求发给服务器。事实上,对于一个虚拟用户来说,每秒发出多少请求只跟服务器返回响应的速度有关。如果虚拟用户在0.5秒内收到了响应,那么它会立即发出第二个请求;而如果要一直等待3秒才能得到响应,它将会一直等到收到响应后才发出第二个请求。也是说,并发用户数的设置只是保证服务器在任一时刻都有100个请求需要处理,而并不一定是保证每秒中发送100个请求给服务器。
所以,只有当响应时间恰好是1秒时,并发用户数才会等于每秒请求数;否则,每秒请求数可能大于并发用户数或小于并发用户数。
无所不在的性能测试
提到性能测试,相信大家可以在网上找到很多种不同的定义、解释以及分类方法。不过归根结底,在大多数情况下,我们所要做的性能测试的目的是“观察系统在一个给定的环境和场景中的性能表现是否与预期目标一致,评判系统是否存在性能缺陷,并根据测试结果识别性能瓶颈,改善系统性能”。
本文是《LoadRunner没有告诉你的》系列的第五篇,在这篇文章中,我希望可以跟大家一起来探讨“如何将性能测试应用到软件开发过程的各个阶段中,如何通过尽早的开展性能测试来规避因为性能缺陷导致的损失”。
因此,本文的结构也将依据软件开发过程的不同阶段来组织。
另外,建议您在阅读本文前先阅读本系列文章的第三篇《理发店模型》和第四篇《理解性能》。
需求阶段
我们不可能将一辆设计载重为0.75吨的皮卡改装成载重15吨的大型卡车,如果你面对的正是这样的问题,那么恐怕你只能重做一辆,而且客户不会为你之前那辆付钱。对于一个已经完成的应用系统来说也是如此。
如果我们在系统结构确定之前能够了解到系统的将要面对的压力,用户的使用习惯和使用频度,我们可以更早也更有效的提前解决或预防可能发生的性能缺陷,也将会极大的减少后期返工和反复调优所带来的工作量。如果我们预期到系统的容量将会不断的增长,我们还可以给出相应的解决方案来低成本的解决这类问题,像上面那辆皮卡,也许你可以有办法把20辆皮卡捆在一起,或者把15吨的东西分由20辆来运。
分析设计阶段
系统性能的优化并不是要等待整个系统全部集成后才能开始的,早在分析设计阶段,我们可以开始考虑系统的技术架构和数据库部分的优化。
数据库通常位于整个系统的底层,如果直到系统上线前才发现因为数据库设计不合理而导致性能极差,通常使用任何一种方法来优化都已经于事无补了。要避免这类问题,常见的做法是在数据库结构确定后,通过工具或脚本向数据库中注入大量的数据,并模拟各种业务的数据库操作。根据对数据库性能的观察和分析,对数据库表结构和索引进行调整以优化数据库性能。
在系统的技术架构方面,要明白先进的技术并不是解决问题的方法,过于强调技术的作用反而会将你带入歧途。例如:某些业务虽然经常面临着巨大的压力,并且业务本身的复杂性决定了通过算法的优化来提高系统的性能收效甚微。但是我们知道用户对于该业务的实时性要求并不高,并且返回结果对于不同用户来说是相同的。那么我们完全可以考虑将每次请求都动态生成返回结果的方式改为每次用户请求都返回一个定期更新的静态页面。
另外,所谓“先进技术”通常都会在带来某一方面改进的同时带来另一方面的问题,未经试验盲目的在系统中加入各种流行元素未必是好的选择。例如ORM可以提供一些方便,但是它生成的SQL是未经优化的,有时甚至比人工编写的SQL效率更低。
后,要知道不同厂家的设备性能是不同的,而且不同的硬件设备搭载不同的操作系统、数据库、中间件以及应用服务器,表现出来的性能也是不同的。如果有足够的资源,应当考虑提前进行软硬件平台的对比选型;如果没有足够的资源,可以考虑通过一些专业的组织或网站来获取或购买相关的评估报告。
编码阶段
一片树叶在哪里难被发现?——当这片树叶落在一堆树叶里面的时候。
如果你只是在系统测试完成后才开始性能测试,那么即使发现系统存在性能缺陷,并且已经有了几个可供怀疑的对象,但是当一段因为使用了不当的算法而导致执行效率很低的代码藏身于一个庞大的系统中时,找出它是非常困难的。避免这种情况出现的方法是尽早开始核心业务代码的性能测试,重点集中在对算法和实现方法的优化上。
另外,及早开始的测试也可以帮你更容易找到内存泄漏的问题。
测试阶段
产品终于交到我们手上了,搭建测试环境,设计测试场景,执行测试,找到系统的佳并发用户数和大并发用户数,将系统进行分类,评判系统的性能表现是否满足需求中定义的目标——如果有需求的话^_^
如果发现系统的性能表现与预期目标相去甚远,则需要根据执行测试过程中收集到的数据来分析和识别性能瓶颈,优化系统性能。
在这个阶段还有很多值得我们深入思考和讨论的东西,在本系列后续的文章中,我们将会更多的关注这一部分的内容。
维护阶段
维护阶段通常遇到的问题是需要在实验室中模拟客户环境,重现在客户那里发现的缺陷并修复缺陷。相比功能缺陷,性能缺陷与某一具体环境和场景的关联更加密切,所以在测试前需要检查生产环境中各服务器的资源利用率、系统访问日志、应用服务器的日志、数据库的日志。如果客户使用了专门的系统来监测各个服务器的软硬件资源使用情况的话,检查该系统是否记录下了软硬件资源的异常或者警告。
与性能测试相关的其他测试
可靠性测试(Reliability Testing)对于一个运营商级的系统来说,能够保证提供7×24的连续稳定的服务是非常重要的。当然,你可以通过一些“高可用性(High Availability)”技术方案来增强系统的可靠性,但是对于系统本身的可靠性测试是不能被忽略的。
常用的测试方法是使用一定的负载长时间向服务器加压,并观察随着加压时间的延长,响应时间、吞吐量以及资源利用率的变化。要注意的是,所使用的负载应当是系统的佳并并发用户数,而不是大并发用户数。
可伸缩性测试(Scalability Testing)对于一个系统来说,在一个给定的环境下,它的佳并发用户数和大并发用户数是客观存在的,但是系统所面临的压力却有可能随上线时间的延长而增大。例如,一个在线购物站点,注册用户数量不断增多,访问站点查询商品信息和购买商品的人也不断的增多,我们应该用一种什么样的方案,在不影响系统继续为用户提供服务的前提下来实现系统的扩容?
一种常用的方案是使用负载均衡(Load Balance)和集群(Cluster)技术。但是在我们为客户提供这种方案之前,需要先自己进行测试,保证该技术的有效性——我们是否真的可以通过简单的增加服务器数据和修改某些参数配置,能够使得系统的容量得到线性的增长?
可恢复性测试(Recoverability Testing)虽然我们已经可以准确的估算出系统上线后将要面对的压力,并且可以保证系统的佳并发用户数和大并发用户数是足以应对这些压力的,但是这个世界上总是有些事情上我们所无法预料到的——例如9.11事件发生后,AOL的网站访问量在短时间内增长到了平时的数十倍。
我们无法保证系统可以在任何情况下都能为用户正确无误的提供服务,但是我们需要确保当意外过去后,系统可以恢复到正常的状态,并继续后来的用户提供服务——像从未发生过任何事情一样。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com