
从性能的角度谈SQL Server聚集索引键的选择
作者:网络转载 发布时间:[ 2015/12/21 14:15:42 ] 推荐标签:性能测试 数据库
简介
在SQL Server中,数据是按页进行存放的。而为表加上聚集索引后,SQL Server对于数据的查找是按照聚集索引的列作为关键字进行了。因此对于聚集索引的选择对性能的影响变得十分重要了。本文从旨在从性能的角度来谈聚集索引的选择,但这仅仅是从性能方面考虑。对于有特殊业务要求的表,则需要按实际情况进行选择。
聚集索引所在的列或列的组合好是的
这个原因需要从数据的存放原理来谈。在SQL Server中,数据的存放方式并不是以行(Row)为单位,而是以页为单位。因此,在查找数据时,SQL Server查找的小单位实际上是页。也是说即使你只查找一行很小的数据,SQL Server也会将整个页查找出来,放到缓冲池中。
每一个页的大小是8K。每个页都会有一个对于SQL Server来说的物理地址。这个地址的写法是 文件号:页号(理解文件号需要你对文件和文件组有所了解).比如第一个文件的第50页。则页号为1:50。当表没有聚集索引时,表中的数据页是以堆(Heap)进行存放的,在页的基础上,SQL Server通过一个额外的行号来确定每一行,这也是传说中的RID。RID是文件号:页号:行号来进行表示的,假设这一行在前面所说的页中的第5行,则RID表示为1:50:5,如图1所示。
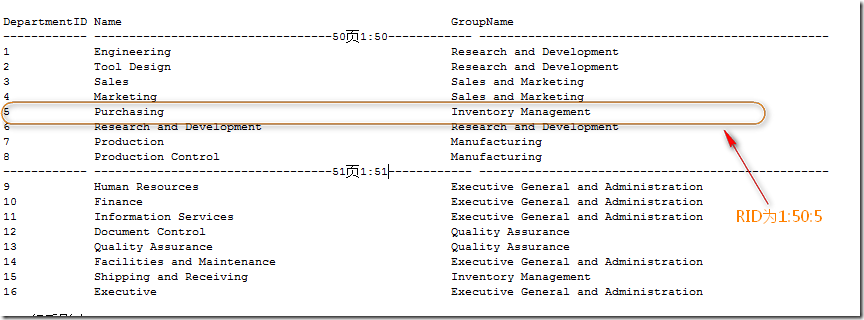
图1.RID的示例
从RID的概念来看,RID不仅仅是SQL Server确定每一行的依据,也是存放行的存放位置。当页通过堆(Heap)进行组织时,页很少进行移动。
而当表上建立聚集索引时,表中的页按照B树进行组织。此时,SQL Server寻找行不再是按RID进行查找,转而使用了关键字,也是聚集索引的列作为关键字进行查找。假设图1的表中,我们设置DepartmentID列作为聚集索引列。则B树的非叶子节点的行中只包含了DepartmentID和指向下一层节点的书签(BookMark)。
而当我们创建的聚集索引的值不时,SQL Server则无法仅仅通过聚集索引列(也是关键字)确定一行。此时,为了实现对每一行的区分,则需要SQL Server为相同值的聚集索引列生成一个额外的标识信息进行区分,这也是所谓的uniquifiers。而使用了uniquifier后,对性能产生的影响分为如下两部分:
SQL Server必须在插入或者更新时对现在数据进行判断是否和现有的键重复,如果重复,则需要生成uniquifier,这个是一笔额外开销。
因为需要对相同值的键添加额外的uniquifier来区分,因此键的大小被额外的增加了。因此无论是叶子节点和非叶子节点,都需要更多的页进行存储。从而还影响到了非聚集索引,使得非聚集索引的书签列变大,从而使得非聚集索引也需要更多的页进行存储。
下面我们进行测试,创建一个测试表,创建聚集索引。插入10万条测试数据,其中每2条一重复,如图2所示。

图2.插入数据的测试代码
此时,我们来查看这个表所占的页数,如图3所示。
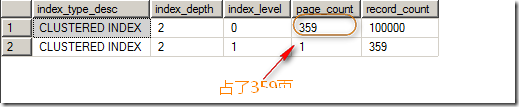
图3.插入重复键后10万数据占了359页
我们再次插入10万不重复的数据,如图4所示。

图4.插入10万不重复的建的代码
此时,所占页数缩减为335页,如图5所示。
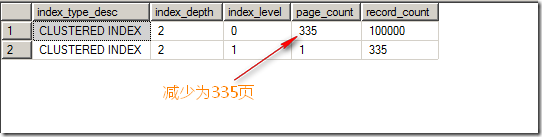
图5.插入不重复键后缩减为335页
因此,推荐聚集索引所在列使用键。
好使用窄列或窄列组合作为聚集索引列
这个道理和上面减少页的原理一样,窄列使得键的大小变小。使得聚集索引的非叶子节点减少,而非聚集索引的书签变小,从而叶子节点页变得更少。终提高了性能。
使用值很少变动的列或列的组合作为聚集索引列
在前面我们知道。当为表创建聚集索引后。SQL Server按照键查找行。因为在B数中,数据是有序的,所以当聚集索引键发生改变时,不仅仅需要改变值本身,还需要改变这个键所在行的位置(RID),因此有可能使得行从一页移动到另一页。从而达到有序。因此会带来如下问题:
行从一页移动到另一页,这个操作是需要开销的,不仅如此,这个操作还可能影响到其他行,使得其他行也需要移动位置,有可能产生分页
行在页之间的移动会产生索引碎片
键的改变会影响到非聚集索引,使得非聚集索引的书签也需要改变,这又是一笔额外的开销
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com