
线程上下文切换的性能损耗测试
作者:网络转载 发布时间:[ 2014/6/18 14:20:07 ] 推荐标签:性能损耗测试 性能测试
三个测试类,运行结果如下:
|
Single Thread:
[耗时407ms] counter = 100000001, stopped
[耗时453ms] counter = 100000001, stopped
[耗时412ms] counter = 100000001, stopped
Two Thread Switch:
[耗时161503ms] counter = 100000001, stopped
[耗时164508ms] counter = 100000001, stopped
[耗时164201ms] counter = 100000001, stopped
Multi Threads - 100 Threads:
[耗时3659ms] counter = 100000001, stopped
[耗时3950ms] counter = 100000001, stopped
[耗时3720ms] counter = 100000001, stopped
Multi Threads - 2 Threads:
[耗时3078ms] counter = 100000001, stopped
[耗时3160ms] counter = 100000001, stopped
[耗时3106ms] counter = 100000001, stopped
|
什么是线程上下文切换
上下文切换的精确定义可以参考: http://www.linfo.org/context_switch.html。多任务系统往往需要同时执行多道作业。作业数往往大于机器的CPU数,然而一颗CPU同时只能执行一项任务,为了让用户感觉这些任务正在同时进行,操作系统的设计者巧妙地利用了时间片轮转的方式,CPU给每个任务都服务一定的时间,然后把当前任务的状态保存下来,在加载下一任务的状态后,继续服务下一任务。任务的状态保存及再加载,这段过程叫做上下文切换。时间片轮转的方式使多个任务在同一颗CPU上执行变成了可能,但同时也带来了保存现场和加载现场的直接消耗。(Note. 更精确地说, 上下文切换会带来直接和间接两种因素影响程序性能的消耗. 直接消耗包括: CPU寄存器需要保存和加载, 系统调度器的代码需要执行, TLB实例需要重新加载, CPU 的pipeline需要刷掉; 间接消耗指的是多核的cache之间得共享数据, 间接消耗对于程序的影响要看线程工作区操作数据的大小).
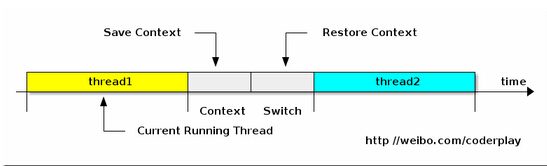
根据上面上下文切换的定义,我们做出下面的假设:
之所以TwoThreadSwitchTester执行速度慢,因为线程上下文切换的次数多,时间主要消耗在上下文切换了,两个线程交替计数,每计数一次要做一次线程切换。
“Multi Threads - 100 Threads”比“Multi Threads - 2 Threads”开的线程数量要多,导致线程切换次数也比后者多,执行时间也比后者长。
由于Windows下没有像Linux下的vmstat这样的工具,这里我们使用Process Explorer看看程序执行的时候线程上线文切换的次数。
Single Thread:

计数期间,线程总共切换了580-548=32次。(548是启动程序后,初始的数值)
Two Thread Switch:
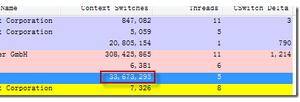
计数期间,线程总共切换了33673295-124=33673171次。(124是启动程序后,初始的数值)
Multi Threads - 100 Threads:

计数期间,线程总共切换了846-329=517次。(329是启动程序后,初始的数值)
Multi Threads - 2 Threads:

计数期间,线程总共切换了295-201=94次。(201是启动程序后,初始的数值)
从上面收集的数据来看,和我们的判断基本相符。
干活的其实是CPU,而不是线程
再想想原来学过的知识,之前一直以为线程多干活快,简直是把学过的计算机原理都还给老师了。真正干活的不是线程,而是CPU。线程越多,干活不一定越快。
那么高并发的情况下什么时候适合单线程,什么时候适合多线程呢?
适合单线程的场景:单个线程的工作逻辑简单,而且速度非常快,比如从内存中读取某个值,或者从Hash表根据key获得某个value。Redis和Node.js这类程序都是单线程,适合单个线程简单快速的场景。
适合多线程的场景:单个线程的工作逻辑复杂,等待时间较长或者需要消耗大量系统运算资源,比如需要从多个远程服务获得数据并计算,或者图像处理。
例子程序:http://pan.baidu.com/s/1ntNUPWP
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com