
分布式测试执行
作者:网络转载 发布时间:[ 2014/6/11 14:37:08 ] 推荐标签:测试技术 分布式测试
1 相关说明
1.1 背景简介
随着一个产品的自动化工作不断深入,自动化的case积累数量持续增长,绝大部分毫无依赖关系的case由于串行运行,测试执行时间达到小时界别,且不易于优化。另外,ci运行时所需机器资源的抢占互斥,运行机器的不稳定等问题也逐渐扩大。
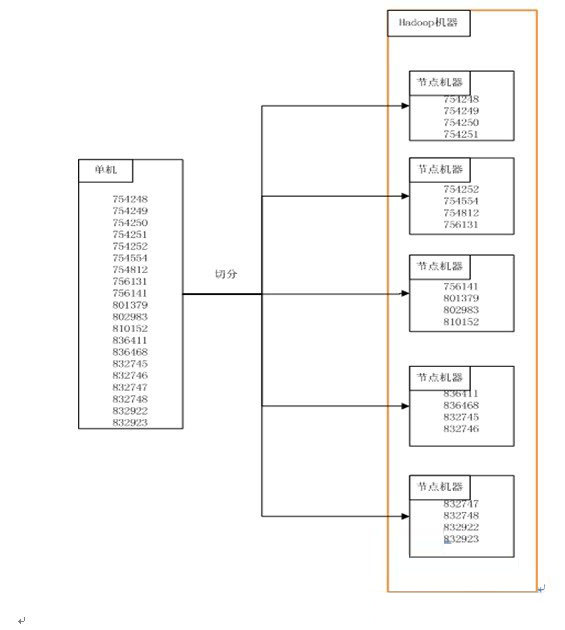
Hadoop分布式测试执行方案正是为了解决以上问题而产生,通过分布式执行,可以达到并行运行,提高执行效率的目的;另外,hadoop提供调度,重试等机制功能,可以提供给用户一个相对透明的计算资源池,减少用户对机器运行环境的依赖。
1.2 分布式平台的选择
本方案采用hadoop来作为分布式平台。首先是Hadoop是一个开源项目,有非常好的技术支持,二是hadoop有成熟的分布式调度算法,可以很好的利用每台机器的cpu和内存资源,达到计算资源优分配,三是hadoop程序易于编写,便于维护。
1.3 名词解释
:apache基金会的开源分布式框架。
Mapreduce :hadoop的计算模型,由map任务和reduce任务组成。
Jobtracker :hadoop计算系统的总控。
Tasktracker :hadoop计算系统的子节点。
Slot(槽位) :tasktracker的小计算分配单元,一个槽位可以对应一个map任务,一个机器启动一个tasktracker,槽位的话按照机器的cpu核数来分配,一般是”核数-1”。
<2 分布式测试执行方案
2.1 传统的单机测试执行流程
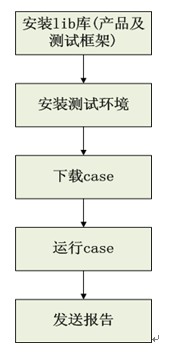
一般的单机测试流程分为5步,如下图所示:
1、lib库安装。包括测试框架的lib库安装以及基于该测试框架的产品业务层lib。
2、测试环境安装。主要指被测对象的测试环境安装,包括数据库安装,server端安装等。
3、case下载。从svn或者case库获取需要执行的case。
4、case运行。
5、发送报告。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com