
HBase性能优化案例分析
作者:网络转载 发布时间:[ 2014/3/31 9:22:35 ] 推荐标签:性能优化 设计 数据 系统
图中c)的架构是在a的基础上的一种改进,Spark使用的是这个架构。HBase的compaction操作可以简化成join和sort这样两个RDD变换。
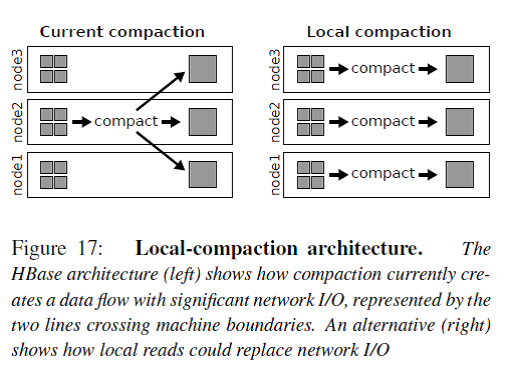
Figure 17展示了local compaction的原理,原来的网络I/O的一半转化成了本地磁盘读I/O,而且可以利用读cache加速。我们都知道在数据密集型计算系统中网络交换机的I/O瓶颈非常大,例如MapReduce Job中Data Shuffle操作是耗时的操作,需要强大的网络I/O带宽。加州大学圣迭戈分校(UCSD)和微软亚洲研究院(MSRA)都曾经设计专门的数据中心网络拓扑来优化网络I/O负载,相关研究成果在计算机网络会议SIGCOMM上发表了多篇论文,但是由于其对网络路由器的改动伤筋动骨,后都没有成功推广开来。
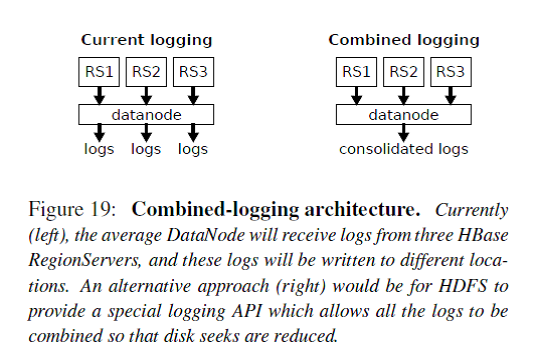
Figure 19展示了combined logging的原理。现在HBase的多个RS会向同一个DataNode发送写log请求,而目前DataNode端会把来自这三个RS的log分别写到不同的文件/块中,会导致该DataNode磁盘seek操作较多(不再是磁盘顺序I/O,而是随机I/O)。Combined logging是把来自不同RS的log写到同一个文件中,这样把DataNode的随机I/O转化成了顺序I/O。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系SPASVO小编(021-61079698-8054),我们将立即处理,马上删除。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11热门文章
常见的移动App Bug??崩溃的测试用例设计如何用Jmeter做压力测试QC使用说明APP压力测试入门教程移动app测试中的主要问题jenkins+testng+ant+webdriver持续集成测试使用JMeter进行HTTP负载测试Selenium 2.0 WebDriver 使用指南

 sales@spasvo.com
sales@spasvo.com