
如何写更好的自动化测试用例
作者:网络转载 发布时间:[ 2014/10/8 11:23:28 ] 推荐标签:软件测试 测试用例
i.首先将外部设备的操作从测试用例步骤中剥离出去,组织成组级别的库.
ii.
c.对测试对象的依赖,这里我考虑到的是如果测试对象是一个软件平台,软件平台通常需要适配多种的设备.而设备的硬件配置可能是多种多样的,CPU、内存、组件的性能和数量都可能不同.
对测试对象的依赖不仅要考虑在不同设备上的可执行性,重点要考虑测试覆盖率,由于设备组件的增多你的用例可能无法覆盖到这些组件,或者捕捉不到某个性能瓶颈,这样测试结果的可靠性也大打折扣.
case的可重用性
自动化用例的开发通常是一项费时的工作,它需要的时间会是手动执行用例的10倍、20倍甚至更多. 我们通过搭建测试框架和封装资源库来实现大范围的可重用性.
这里我考虑用例的可重用性包括两块:逻辑层的抽象和业务层的重用.
对一个产品或者功能进行自动化工作时,我们要考虑这些可用性:首先根据测试逻辑的不同对测试用例进行分类,根据逻辑的不同选择搭建有针对性的case框架,Work Flow, Data Driven等.
建立公共的库,将业务的原子操作抽象出来,并且鼓励其他同事对库进行补充和调用,避免duplicated库开发.抽象的API通常需要足够的原子和灵活才会被大众所接受. 基于底层API编写的业务操作也具备可重用性,比方说测试场景(背景资源)的建立、工作流的操作组合、检查点都可以被复用. 层次分明的抽取时重用性的基础,提高可重用性可以减少开发时间,也方便日后的维护中的迭代修改.
case的效率
不同的case执行时间相距甚远,短则数秒长则数小时甚至数天,数秒钟的简单功能测试用例和稳定性测试耗时数天的用例本身是没有什么可比性的.但是我当我们放眼某一个或者某一组case时,我们需要重视效率.不论是敏捷还是持续集成都讲究快速的反馈,开发人员能在提交代码后快速的获得测试结果反馈,测试人员能在短的时间内执行更大范围的测试覆盖,不仅能提高团队的工作效率也可增强团队的信心.
在编写用例时我们应该注意哪些方面来提高用例的性能?
对于单一的case我的注意点多放在一些细节上,例如:
1.执行条件的检查,如果检查失败,则尽快退出执行.
2.将执行环境搭建或者资源建立和清除 抽取到suite甚至folder level, 抽取时可能需要做一些组合, 但决不允许出现重复的建删操作.
3.用例中不允许出现sleep,sleep通常紧接着hard code的时间,不仅效率低还会因为环境的切换使得执行失败.建议用"wait until ..."来代替.
4.如有不可避免的sleep,我通常会再三确认其是否清楚它的必要性.
对于批量的case,我们要如何才能获得更高的效率呢?
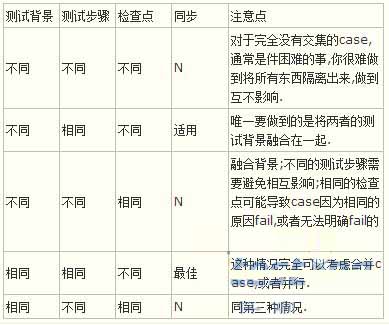
1.首先我们考虑到可以并行的执行一组case来提高效率,并行方案总有着严苛的条件:
2.为了获得更快的反馈,我们将软件质量分为0~10级,对应的把测试用例分为6~10级,从普通的功能测试开始测试复杂度逐级递增.
不同的开发阶段或者是针对不同的测试目的我们可以有选择的调用不同级别的用例.比方说我们调用6级的cases来测试新功能代码作为冒烟测试的用例集;软件人员修改了BUG,我可以根据BUG的复杂度选择7和8级的用例来验证,系统级测试时我们又会主要测试8和9级的用例.
分级可以灵活调度用例,并给出更快的反馈,加速迭代过程.
3.基于风险的测试
基于风险的测试简单的说是根据优先级来选择需要运行的测试,优先级根据两个基本的维度:
功能点发生错误的概率,以及发生错误后的严重性,根据两者分值的乘积来排序优先级.
一般从用例失败率,bug统计,出错的代码段,更新的代码段来考虑调度.比方说根据BUG修改的代码段和功能区域来选择对应的测试.开发人员通常反对这种方式,只有的测试覆盖才能给他们足够的信心.
以上是个人的一些积累,由于框架的限制一些建议不一定适用于你的实际工作. 如果你有什么建议欢迎留言. Thx!
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系SPASVO小编(021-61079698-8054),我们将立即处理,马上删除。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11热门文章
常见的移动App Bug??崩溃的测试用例设计如何用Jmeter做压力测试QC使用说明APP压力测试入门教程移动app测试中的主要问题jenkins+testng+ant+webdriver持续集成测试使用JMeter进行HTTP负载测试Selenium 2.0 WebDriver 使用指南

 sales@spasvo.com
sales@spasvo.com