
如何精确判断终用户响应时间过长的原因?
作者:网络转载 发布时间:[ 2013/9/12 15:40:31 ] 推荐标签:
当两个团队孤立检查,运维导向的监测是不会有这个的结论(Whenexaminedindependently,operations-orientedmonitoringwouldnotbethattelling.)。但是,当它被放到具体的上下文中,并涉及到关联的数据(终用户响应时间,用户体验,...),这对开发团队来说是非常重要的,两个团队将获得更多的灵感和视角。这是一个良好的开端,但仍然还有很多需要了解的。
步骤3:哪些关键事务被真正影响到了?
点击社区应用程序的链接,它会显示实际受硬件状态影响的事务和页面,但仍然存在着两个关键的却又悬而未决的问题:
这些事务,是否是我们成功运行的关键?
这些事务和个人用户受性能问题影响后,有多严重的后果?
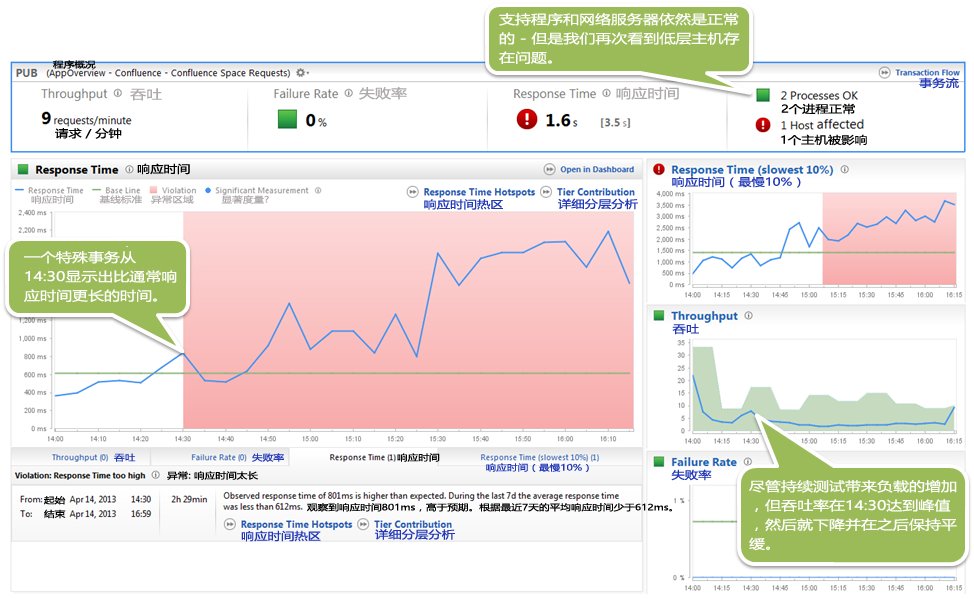
自动基线告诉我们,社区网站主要页面的响应时间受到明显的的性能影响。也包括我们的首页,这是我们有价值的一个页面。
步骤4:可视化受硬件问题影响的事务流
事务流图表是一个令人满意的方式,能使得运维团队和开发团队达到一个基本的共识,并根据其完整的上下文查看关键的数据。它能显示涉及到的应用层,正在运行的物理机器和虚拟机器,以及哪里是热点区域。
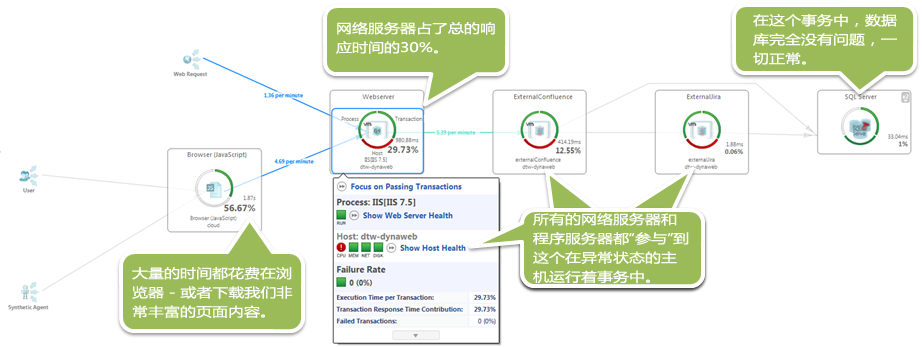
运维团队和开发团队有相同的概要图表,告诉他们无论是在"横向"事务和"纵向"层面的热点区域。
我们知道,我们的网页内容非常"丰富"(图像,JavaScript和CSS),高达80%的事务时间花费在浏览器上。看到热点区域这样的表现,现在整体页面加载时间下降到50%,我们马上知道更多的事务时间已经转移到新的热点区域:服务器端。好消息是,数据库是没有问题的(只用了1%的响应时间),整个性能热点区域似乎转到Web和应用程序服务器,它们都运行在同一台机器上-即那台存在CPU问题的机器。
第5步:精确定位存在问题的机器的健康问题
点击主机健康图表(HostHealthDashboard),它会显示了那个特定的服务器出了什么问题:
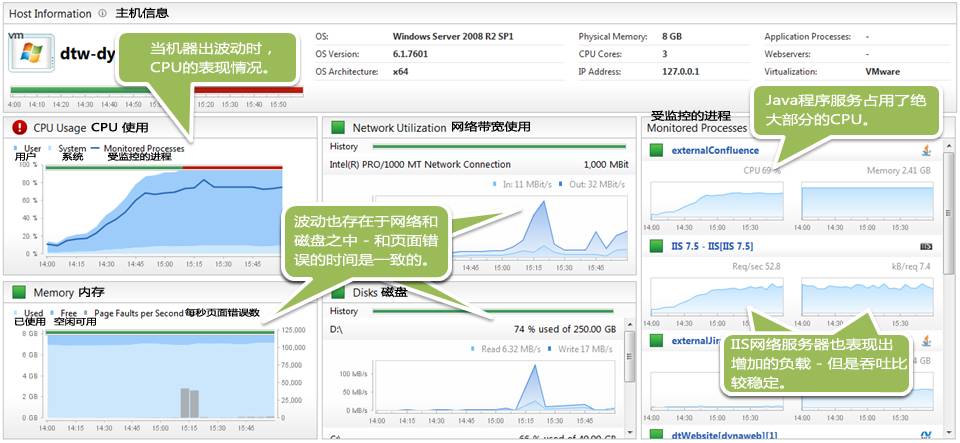
运维团队立即看到了CPU的消耗主要来自于一个Java应用服务器。网络,磁盘和页面错误在一些某些特定的时间也都存在不寻常的波动。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com