
C语言实现合并排序
作者:网络转载 发布时间:[ 2013/4/19 14:41:54 ] 推荐标签:
其基本模式如下:
分解:把一个问题分解成与原问题相似的子问题
解决:递归的解各个子问题
合并:合并子问题的结果得到了原问题的解。
现在用递归算法,采用上面的分治思想来解合并排序。
合并排序(非降序)
分解:把合并排序分解成与两个子问题
伪代码:
MERGE_SORT(A, begin, end)
if begin < end
then mid<- int((begin + end)/2)
MERGE_SORT(A, begin, mid)
MERGE_SORT(A, mid+1, end)
MERGE(A, begin, mid, end)
解决:递归的解各个子问题,每个子问题又继续递归调用自己,直到"begin<end"这一条件不满足时,即"begin==end"时,此时只有一个元素,显然是有序的,这样再进行下一步合并。
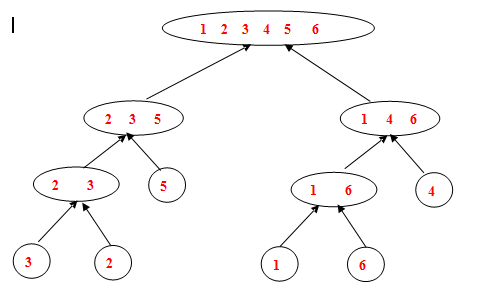
合并:合并的子问题的结果有个隐含问题,即各个子问题已经是排好序的了(从两个氮元素序列开始合并)。做法是比较两个子序列的第一个元素小的写入终结果,再往下比较,如下图所示:

图中:待排序数组为2 4 6 1 3 5
把2 4 6和 1 3 5 分别存到一个数组中,比较两个数组的第一个元素大小小者存于大数组中,直到两小数组中元素都为32767.
这里32767 味无穷大,因为c语言中int类型是32位,表示范围是-32768-----32768。用无穷大作为靶子可以减少对两个小数组是否为空的判断,有了靶子,直接判断大数组元素个数次排完了。
在整个过程中执行过程示如下图:
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com