
在测试中怎样对的测试数据进行建模
作者:网络转载 发布时间:[ 2013/1/8 15:22:07 ] 推荐标签:
现在很多软件应用,都设计成2部分:应用程序Application + 数据库DB。要对这种类型的应用软件进行测试,“测试数据”这个概念非常的关键。测试用例中的“前置条件”,基本是围绕测试数据来设计的。以淘宝网的测试为例,验证每个功能点时,重要的是准备好各种类型的数据对象,比如:不通信用级别的卖家,不同类目属性的商品等等。
熟练的测试工程师手里都会保存一批测试数据(比如账号、商品),并且分类管理,不同场景的测试用例,都会有专门的测试数据来支持。在ta的心里,存在着一套完整的测试设计方案,在工作中也会显得游刃有余。要达到这种状态,需要经过一段时间的积累,需要“磨合”。对测试数据的控制力,也是测试工程师的重要能力之一,可惜这种能力很难被识别,被比较。
近2年,软件测试工作在逐渐向开发团队转移,由以前的测试团队“全包”,变成了现在的“半包”。很多观点也认为,开发团队来做测试工作,有着得天独厚的优势,因为开发对应用程序的结构熟悉,哪里容易出现问题也清楚。当然也有很多开发表示反对,原因大概有下面几个:
没时间,能把代码写完不错了
开发工程师没有测试工程师的那种思维方式
测试数据准备起来比较困难
这里的“测试数据问题”是客观存在的,但不仅仅是这么简单的一句话可以概括,需要深入分析。我们观察开发工程师在做测试工作的时候,在测试数据方面会遇到下面几个问题:
对于一些比较复杂的测试场景,搞不清应该构造哪些测试数据对象,后只好随便抓一个来测试,只要没抛异常,算pass;
算搞清了测试数据的需求,去哪找这些数据,仍然是一个大问题,后还是随便抓一个来测试;
算把所有的测试数据都做好,如何根据测试场景随机应变的使用,如何维护这些数据始终有效,也非常不容易;
分析到这里我们发现,测试工程师对测试数据的控制能力,真的不简单,开发工程师在工作中一般没有接受过类似的训练,所以很容易陷入“测试数据”的泥潭。而且,这个问题跟人的能力有关,不是单纯依靠工具能解决的。关于“测试数据建模”,主要是解决上面的第一个问题:当我们要测试一个功能点,或者一系列场景的时候,需要设计出怎样的测试数据组合。
我们先假设一个简单的场景,这个场景只需要用到1个数据对象:USER,那么这里的测试数据,是USER的每个属性的枚举值:性别、年龄、状态、等级,我们用一句话可以概括一个数据对象,比如:女性user、20岁的user、状态是已认证的user。测试用例可以这样写,但是实际测试时,熟练的测试工程师并不会分别测试,而是把多种情况组合在一起,比如:20岁的已经认证的女性user。每个人的组合方式都不一样。有一种算法叫做“Pairwise Testing”,可以比较科学的组合多个属性的枚举值。但是有经验的测试工程师发现,年龄和性别的逻辑关系很密切,这里的组合需要特别的设计,依靠Pairwise的基础设计还远远不够,需要引入业务逻辑的分析。
所以同样的测试用例,不同的工程师在测试时,花费的时间,得出的结果,会有很大的不同。仅仅一个数据对象,会产生这么复杂的情况,那么请设想一下,如果一个场景需要用到5个数据对象,并且它们之间存在复杂的逻辑关系时,测试工程师需要面临怎样的困难局面,我们已经无法用一句话来概括测试数据的具体值。这里“测试数据建模”的概念自然的引出了,建模的目的,是我们可以很容易的描述清楚,复杂场景下的测试数据是怎样的。
很多工程师习惯用思维导图来进行测试数据的设计,比如上文那个例子,大家会看到这样的设计图:

但是在真实的测试场景中,我们使用的是matrix来组织测试数据,如下:
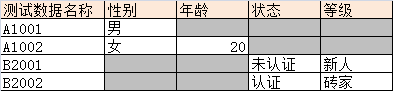
灰色的cell代表在这个场景下,该属性随便取什么值。在这个案例里,我们发现性别和年龄关系密切,而状态和等级关系密切,所以测试数据需要分开设计,我们建立A、B两个模型:
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com