
应用MapReduce制作压力测试利器
作者:网络转载 发布时间:[ 2013/11/7 10:10:59 ] 推荐标签:
引言
众所周知,MapReduce编程框架(以下简称MR)一直是大并发运算以及海量数据读写应用设计的利器。在MR编程体系下,一个job通常会把输入的数据集切分为若干块,由map task以完全并行的方式处理消化这些数据块。框架会对map的输出先进行排序,然后把结果作为输入提交给reduce任务。通常作业的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和监控,以及重新执行已经失败的任务。典型的MR程序有如下重要模块结构构成:
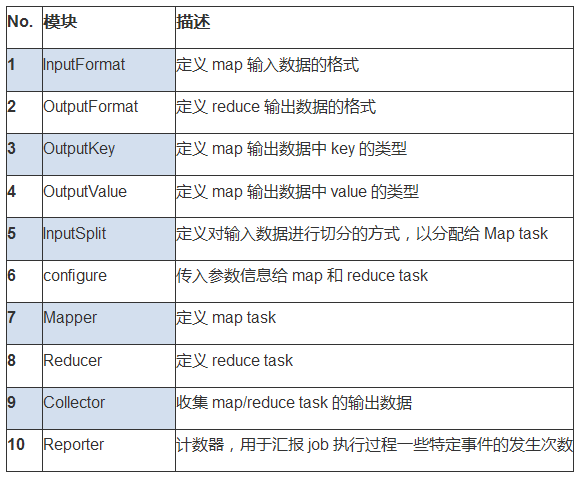
类似hive这样的应用,拿到用户一句简单sql查询(假设无需二次执行的简单sql)后,将hdfs上的海量数据进行切分,然后每个map task分别对自己负责的那部分数据执行相同的sql查询,后将各自获得的结果汇总输出给用户,这便可以保证在海量数据中以较快的速度获得查询结果。
简单介绍完MR编程框架后,我们再来谈谈常规压力测试的特点和需求。
以LoadRunner和JMeter为例,这两种工具都可以对web应用进行大并发访问,模拟线上的高并发压力测试,并且也都相应的提供了多机联合产生负载这样的方式进一步模拟现实情况增大被测对象的压力。这是为了解决“如果一台测试机器模拟的虚拟用户数过多,他本身性能的下降也会直接影响到测试效果”这个问题。分析LR和JMeter的多机联合产生负载这种测试方式,我们不难发现类似MR框架的一些特点,即测试分作如下几步(以LR为例):
1. 设置测试机,即在多台用于测试的机器上安装Load Generator
2. 设置测试任务,即各种configure
3. 同时调度测试任务,通过agent执行对web应用的访问
4. Controller负责统一调度运行场景并收集测试信息和执行结果
无论是LR还是JMeter都是的压测工具,但是总有一些非常规的压力测试场景无法通过LR或JMeter方便的实现,例如对分布式系统做数据读写压力测试,被测目标并非一个单独的节点,而是由很多节点组成的,这样的压力测试场景意味着多机联合对单一节点产生的负载被分担到了很多个节点上。LR和JMeter针对这样的场景往往在设置上很复杂。
此外,对很多特定的压测目标,测试人员在设计了专属测试工具之后,往往也需要有一个类似上述LR测试步骤的过程,即工具分发、调度执行、收集结果和过程信息这样一个测试执行框架,如果自己去实现这一套框架,耗费的人月数都是相当可观的,且复用程度有限。于是在云梯项目中我通过自己的实践,想到了将MR编程框架体系与压力测试需求相结合。
从事例说起
先从简单实现类似LR多机联合负载这样一个压测场景展开。被测目标是这样的:一个web应用服务,用于收集分布式系统的跨机房流量信息,后端采用hbase作为存储数据库,接口为单一节点的http listen端口,需要模拟真实跨机房场景,利用较少的机器数量(约真实系统的50分之一)模拟线上系统的并发度。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com