
性能测试新手误区
作者:薛定谔的破猫 发布时间:[ 2012/6/13 9:32:02 ] 推荐标签:
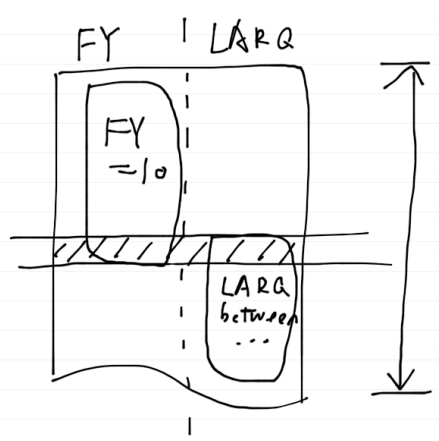
但在本例中不正常的数据条件下,数据库会知道:符合N_FY查询条件的数据有50万条,符合D_LARQ的也有近50万条,如果使用其中一列的索引将一百万的范围缩减到50万,比从头到尾扫描整个表做的工作还要多(为什么呢?需要了解索引的结构和原理),那还是不要用索引了吧。于是数据库会依次检查每一条数据,判断N_FY和D_LARQ是否符合条件。
如图二所示。
图二
注:本图中实际扫描的数据量是整张表的数据,但结果集和图一是一样大的。
这样,可以知道,总数据量一样,结果集大小一样,为什么性能差了很多了。是因为数据分布不合理,导致数据库无法正常使用索引,从而进行了全表扫描。当然,这个数据分布,我们依然可以归类到结果集中去,那是要保证每一个查询条件“单独的结果集”都要符合真实情况,而不仅仅是整个查询终的“总结果集”。
看个这两个简单的小例子,我们再来总结一下关于测试数据,需要注意的内容:
根本、也是大家都知道的是数据量,性能测试必须保证能在预期的数据量下进行测试。在一万条记录中查询,和在一百万数据中查询,显然是大大不同的,可以把数据量看做一种“压力”,这个不用再解释了。
但是在比较大型的系统中,这一点可能也不是很容易做好,因为这类系统往往有着复杂的数据库,上百张的数据表。对每张表都进行数据模拟显然是不现实的,也是没有意义的,因为不是每张表都涉及到大数据量。那么如何选取不容易遗漏呢?通常通过两种方式:从设计和业务角度分析表间关系、从现有实际数据量进行分析推测。
确保结果集在正常范围内。结果集的大小直接影响后续很多工作的性能,如数据排序分组、分页、程序中的逻辑校验或者是展现。
数据分布必须合理,尽量接近真实。数据的分布,其实也是数据的真实性,它直接决定了数据库是否使用索引、选用哪个索引,也是常说的查询计划。不同的查询计划也是不同的数据访问路径,性能差别可能会很大。
这里主要涉及到的是索引的问题,需要大家对索引的原理有一定的了解,索引如何工作、数据库如何选择索引、和索引有关的一写重要概念如区分度(selectivity)等等。
好的数据来自生产环境。这是显而易见的,使用真实的数据测出来的结果才是准确的。但是绝大多数情况下,我们没有这样的好运,可能是客户禁止、也可能是生产环境数据量比较小。那只好自己想办法来模拟了,需要注意的也是上面说到的几点。这里再推荐一种方法,数据翻倍。比如已经有了真实的数据十万条,但我们需要一百万条,那可以通过写一些SQL或者存储过程,将现有的数据不断翻倍(简单的说,复制到临时表,根据需要修改一些列,再插回到原表),这样的数据真实性还是比较高的。
关于测试数据,我想说的是以上几点了。另外再补充上一些相关内容,也是性能测试人员需要关注的。
重点了解IO的概念,更准确的说应该是物理IO。一般来讲,数据库的瓶颈或者查询的主要耗时是IO。所以,数据库优化的一个重要方向是尽量减小IO。
IO是不是只和数据量(行数)有关呢?举一个例子:
select co1, col2, col3, col4, col5 from T_AJ
where condition...
T_AJ数据量有100万,表中有近200列,此查询耗时大于10秒。而另一种实现方式,首先将col1-col5以及查询条件中的几个列的数据抽取到一张临时表(#T_AJ)中。然后,
select co1, col2, col3, col4, col5
from #T_AJ where condition...
临时表#T_AJ和原数据表有同样的数据量(行数),但是此查询却只需要1秒(暂不考虑抽取到临时表的耗时),这是不同IO引起的差异。通常我们使用的数据库都是行式存储的,可以简单的理解为,一行数据从头读到尾,才能进入到下一行。这样,不管一行中的200列,你只读取其中的一列还是几列,其余的190多列仍然需要一定的IO。在大数据量下,这个性能差异很明显了。所以上面的这个例子是一种典型的优化手段,索引覆盖也是处理类似问题的典型方法,各位自行了解吧。列式存储数据库(如Sybase IQ)之所以性能这么高,也是同样的道理。
- 尽量深入了解这些概念,如执行计划,基于开销的估算,统计信息等等。我用一句话来简单描述:数据库通过统计信息来估计查询开销,统计信息不准时,开销估计可能不准确,从而导致选择了错误的执行计划。
- 测试过程中数据的清理。性能测试过程中可能又会生成大量的数据,积累到一定程度又会对性能结果造成影响,所以每一轮测试时都应该清理掉之前测试过程中产生的数据,保证每次测试是在相同的条件下进行的。
- 性能测试过程中,如果定位到了某一个查询或SQL有问题,首先要确认的是数据是否合理。通过查询计划来判断是否按预期进行了查询,如果不是,查看数据的分布是否真实。一般数据库会提供很多种手段来进行验证。
性能测试新手误区(三):用户数与压力
同样的项目、同样的性能需求,让不同的测试人员来测,会是相同的结果么?
假设有这样一个小论坛,性能测试人员得到的需求是“支持并发50人,响应时间要在3秒以内”,性能测试人员A和B同时开始进行性能测试(各做各的)。
只考虑发帖这个操作,A设计的测试场景是50人并发发帖,得到的测试结果是平均完成时间是5秒。于是他提出了这个问题,认为系统没有达到性能期望,需要开发人员进行优化。
B设计的测试场景是,50个人在线,并且在5分钟内每人发一个帖子,也是1分钟内有10个人发帖子,后得到的测试结果是平均完成时间2秒。于是他的结论是系统通过性能测试,可以满足上线的压力。
两个人得到了不同的测试结果,完全相反的测试结论,谁做错了?
或许这个例子太极端,并发和平均分布的访问压力当然是截然不同的,那我们再来看个更真实的例子。
还是一个小论坛,需求是“100人在线时,页面响应时间要小于3秒”。A和B又同时开工了,这时他们都成长了,经验更加丰富了,也知道了要设计出更符合实际的测试场景。假设他们都确认了用户的操作流程为“登录-进入子论坛-(浏览列表-浏览帖子)×10-发帖”,即每个用户看10个帖子、发一个帖子。于是他们都录制出了同样的测试脚本。
A认为,每个用户的操作,一般间隔30s比较合适,于是他在脚本中的每两个事务之间加上了30秒的等待(思考时间)。
B想了想自己看论坛时的情景,好像平均每次鼠标点击要间隔1分钟,于是他在脚本中的每两个事务之间加上了1分钟的等待。
他们都认为自己的测试场景比较接近实际情况,可惜测试结果又是不同的,很显然A场景的压力是B的两倍。那谁错了呢?或者有人说是需求不明确导致的,那么你需要什么样的需求呢?
看看我随手在网上(51testing)找的提问吧,和上面的内容如出一辙。一定有很多的性能测试人员每天接到的是这种需求,又这样开展了测试,结果可想而知。
这里我想问几个问题,希望各位看完了上面的小例子后想一想:
如果有另一个人和你测同样的系统,你们的测试结果会一致么?
如果不一致,那么谁是正确的?
如何证明测试结果是有效的?
如果你有了一些疑惑,对之前的测试结果少了一些自信,那么请继续。
服务器视角 vs. 用户视角
性能测试中非常重要的一块内容是模拟预期的压力,测试系统运行在此压力下,用户的体验是什么样的。
那么压力是什么?压力是服务器在不断的处理事情、甚至是同时处理很多事情。压力是服务器直接处理的“事情”,而不是远在网络另一端的用户。












 sales@spasvo.com
sales@spasvo.com