
测试用例的自动生成技术
作者:网络转载 发布时间:[ 2012/12/28 10:35:52 ] 推荐标签:
第二步,整理出所有输入数据的取值范围,这里要把我们生平所学的所有业务知识、测试理论全都用上,什么等价类啊,边界值啊,随便吧,总之八仙过海各显神通,不过这里数据取的不好是会影响测试用例质量的哦!(PS:数据库字段数据的取值范围有个偷懒的办法,可以去线上库distinct一下,立马有了):
| 输入数据 | 类型 | 取值范围(包含异常取值) | 取值个数 |
| nick | String |
“”,空串 null “1233211”,不存在的用户nick “leizang_test”, 淘宝帐号 “leizang_btob_1”,B2b帐号 “ leizang_btob_1:subnick01”, 子帐号 |
6 |
| suspended | Integer | 0,1,2,3,-9 | 5 |
| wwLimitData | String |
null “true” “OK_WW” “ LIMIT_WW” “ {"ruleCode":"","wwuic-limit":"OK_WW"}” “ {"ruleCode":"xxxx","wwuic-limit":"LIMIT_WW"}” |
6 |
| punishData | String |
null "UEsDBBQACAAIAGL/Ua61XfDlBLBwi2PNplVAAAAPwDAAA=" |
2 |
| mmpData | String |
null “{"accountStatus":-1}” “{"accountStatus":3,"owedStatus":-1}” |
3 |
一旦输入范围确定,用例的输入好解决了,笨的办法是把所有的数据排列组合一遍,肯定能测试到所有的场景,只是用例的数量庞大一点而已,排列组合后的用例个数为:6*5*6*2*3= 1080个,哇靠,这么多啊,果然不是人能做出来的,看你以后老板还敢不敢要求脚本数量。不过呢,这里面水分很多,有很多重复场景,那有效场景到底有多少呢?我们先放一放,容后再谈,先来解决一下预期数据的准备问题。
2、解决预期数据问题
梳理流程图,整理出依赖关系,“A-- > B”表示A依赖于B:
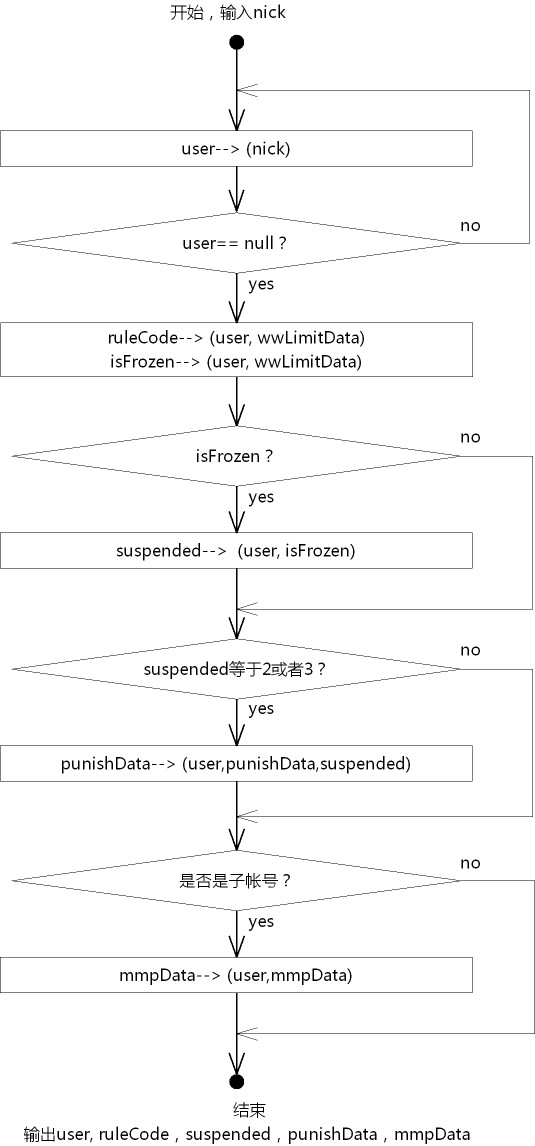
整理出的依赖关系如下:
| 中间对象 | 被依赖对象 |
| user | nick |
| ruleCode | user, wwLimitData |
| isFrozen | user, wwLimitData |
| suspended | user, isFrozen |
| punishData | user, punishData, suspended |
| mmpData | user, mmpData |
这样,我们可以针对每一个“中间对象”(没想到好名字,姑且先这么叫)编写一个获取中间对象取值范围的方法。注意这里用词是“取值范围”,跟开发的程序逻辑是不一样的,是我们根据“输入的数据”并按照“业务规则”得出的,我们直接用数据说话,那么到底该如何编写呢?接着往下看。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系SPASVO小编(021-61079698-8054),我们将立即处理,马上删除。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11热门文章
常见的移动App Bug??崩溃的测试用例设计如何用Jmeter做压力测试QC使用说明APP压力测试入门教程移动app测试中的主要问题jenkins+testng+ant+webdriver持续集成测试使用JMeter进行HTTP负载测试Selenium 2.0 WebDriver 使用指南

 sales@spasvo.com
sales@spasvo.com