
有关T-SQL的10个好习惯
作者:网络转载 发布时间:[ 2012/10/23 10:16:13 ] 推荐标签:
1、在生产环境中不要出现Select *
这一点我想大家已经是比较熟知了,这样的错误相信会犯的人不会太多。但我这里还是要说一下。
不使用Select *的原因主要不是坊间所流传的将*解析成具体的列需要产生消耗,这点消耗在我看来完全可以忽略不计。更主要的原因来自以下两点:
● 扩展方面的问题
● 造成额外的书签查找或是由查找变为扫描
扩展方面的问题是当表中添加一个列时,Select *会把这一列也囊括进去,从而造成上面的第二种问题。
而额外的IO这点显而易见,当查找不需要的列时自然会产生不必要的IO,下面我们通过一个非常简单的例子来比较这两种差别,如图1所示。
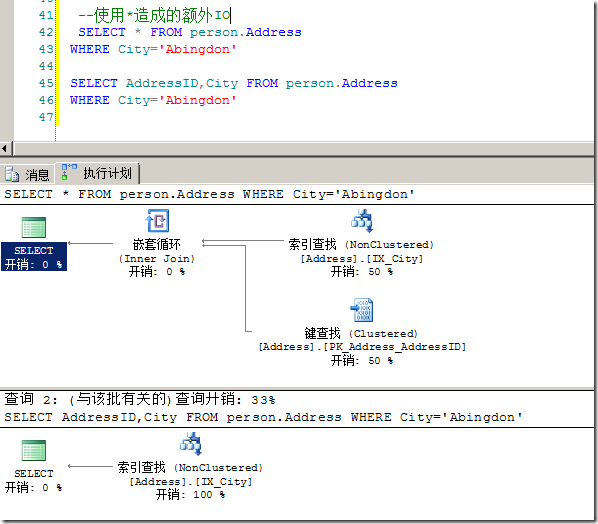
图1.*带来的不必要的IO
2、声明变量时指定长度
这一点有时候会被人疏忽,因为对于T-SQL来说,如果对于变量不指定长度,则默认的长度会是1.考虑下面这个例子,如图2所示。
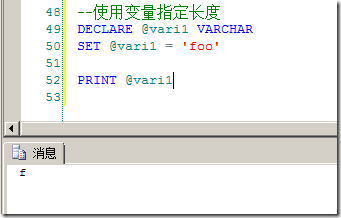
图2.不指定变量长度有可能导致丢失数据
3、使用合适的数据类型
合适的数据类型首先是从性能角度考虑,关于这一点,我写过一篇文章详细的介绍过,有兴趣可以阅读:对于表列数据类型选择的一点思考,这里我不再细说了
不要使用字符串类型存储日期数据,这一点也需要强调一些,有时候你可能需要定义自己的日期格式,但这样做非常不好,不仅是性能上不好,并且内置的日期时间函数也不能用了。
4、使用Schema前缀来选择表
解析对象的时候需要更多的步骤,而指定Schema.Table这种方式避免了这种无谓的解析。
不仅如此,如果不指定Schema容易造成混淆,有时会报错。
还有一点是,Schema使用的混乱有可能导致更多的执行计划缓存,换句话说,是同样一份执行计划被多次缓存,让我们来看图3的例子。
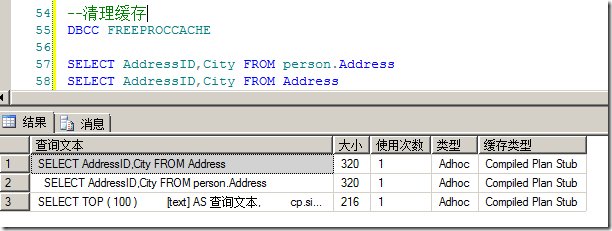
图3.不同的schema选择不同导致同样的查询被多次缓存
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com