
性能测试新手误区(二):为什么我模拟的百万测试数据是无效的?
作者:网络转载 发布时间:[ 2012/10/10 13:11:20 ] 推荐标签:
测试环境的重要性无需多说,大家都知道测试环境要尽量的模拟生产环境,当然也包括数据。这样测试的结果才会更加准确的反应真实的性能。连开发过程,都已经开始在大数据量下加压开发了。那么,关于测试数据,你了解多少呢?
通常说的测试数据可以分为两类:
一是为了测试性能而准备的数据,这是用来模拟“压力”的数据。也是常说的数据量、历史数据等。一般都会根据需求或者经验很容易估算出来,比如案件年增长量为5%,去年数据量为100W,测试需要保证3年后系统仍可正常运行,那么需要计算并模拟出3年后的总数据量,在这个基础上进行测试。
二是用来辅助测试使用的数据。比如有一个对案件进行打分的功能,只有符合一定条件的案件才会出现在打分列表中。那么我们要测这个打分的操作,首先要保证有可用的案件,这需要去生成测试数据,该数据可能一经使用失效了(已经打过分不能再打了)。这样,每次测试这个功能,需要准备这样一批数据。这里的测试数据,更多的是和测试流程有关,是为了能够正常的进行测试,而不是涉及到性能的。
我们这里要说的是第一类,对性能测试结果产生直接影响的数据。
先看两个小案例,涉及到了案件表(T_AJ)和法院编号列(N_FY)、立案日期列(D_LARQ)。案件表中模拟了一百万测试数据,测试简单的查询操作,根据经验,预期响应时间在2秒之内。
案例1.查询本院案件列表,相应的SQL如下:
select*fromT_AJ
whereN_FY=10
orderbyD_LARQdesc
执行这个操作耗时近10s,显然达不到正常预期。
经排查,生成的100W测试数据中,所有的N_FY列值都为10。这样,明显的问题是,查询的结果集数量完全偏离了正常范围。如果实际有100家法院,正常分布下,每家法院只有1W的案件,但测试数据的FY只有一个值,通过这个查询,查出了原来100家法院的数据。无论是在数据库处理中(如本例的排序),还是在程序的处理中(如展现或者是对数据做进一步处理),两者的性能差异都是很显著的。所以这个测试结果是无效的。
有人说,这个例子太弱了,结果集差了100倍,性能当然不一样了。那是不是数据总量和结果集大小都一致,测试结果是有效了呢?
案例2.查询本院一个月内收的案件,相应SQL如下:
select*fromT_AJ
whereN_FY=10andD_LARQbetween'20110101'and'20110201'
这个操作,查出来的结果只有一千条数据,属于正常范围。但查询的时间还是超过5秒,依然超出了我们的预期。
查看数据发现,N_FY=10的数据有近50万,占了总数据量的一半,D_LARQ在一月份的数据也占了差不多一半。但是同时符合两个条件的数据还是一千条左右。那么这里的问题不在于结果集了,而是是否能利用索引进行查询,看如下两个图能很好理解了。
在正常数据中,每家法院的数据可能占总数据量的1%,一个月时间段内的数据可能占总数据量更少,假设是0.5%。那么这时我们通过N_FY和D_LARQ两个条件进行查询,数据库会进行估算:符合D_LARQ查询条件的数据大概有5000条,符合N_FY查询条件的数据大概有1万条,那么用D_LARQ上的索引进行查询是快的,可以迅速的将查询范围缩小到5000条,然后在这5000条中去检查N_FY是否也符合条件。
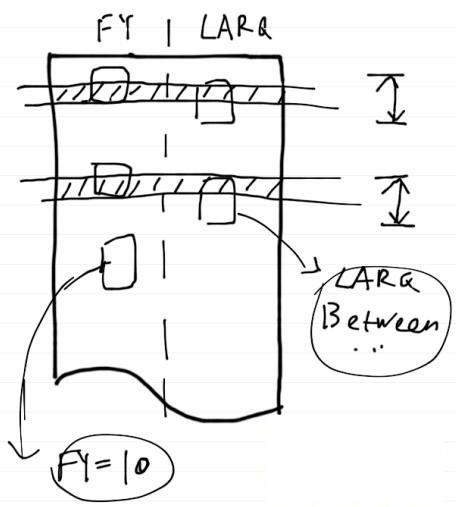
注:数据按行存储,小方块表示符合该列查询条件的数据,阴影表示符合所有查询条件,也是终的结果集。箭头线段表示为了完成查询,需要扫描的数据量,本图中即符合LARQ查询条件的数据。下同。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com