
SQL LIKE语句多条件贪婪匹配算法
作者:网络转载 发布时间:[ 2012/10/10 10:59:08 ] 推荐标签:
在CMS开发中,经常会有类似这样的需求:
提问——回答模式,经典的例子是百度提问。
提问者提出问题,由其他人回答,其他人可以是用户,也可以是服务商。
在这个模式中,如何充分利用历史数据是关键的技术。很多时候,由于客户不擅长使用搜索功能,一上来提问,而这些问题往往早已经有近乎完美的答案,但没有充分利用。这样一来,不仅加大了劳动量,又增加了数据冗余。
如果在提问的时候能充分调动历史数据,提交问题之前先看看历史问题能不能解决客户疑问,解决了,好不过,解决不了,再提交。百度提问是采用的这种方案:
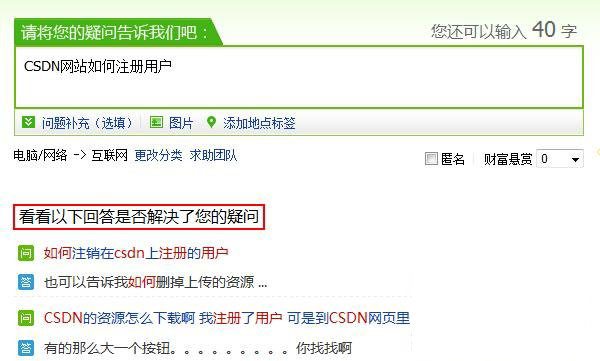
模式固然好,可怎么实现有些困难了,毕竟这是百度作为搜索引擎的看家本领。
从上图可以看出“CSDN网站如何注册用户”这句话被拆成了N个词,然后分开去数据库中匹配,为什么?因为直接去匹配“CSDN网站如何注册用户”这句话,汉语博大精深,稍微变动一下:“如何在CSDN网站注册用户”,意思完全一样,但直接匹配匹配不到!
因此,我们需要把一句话拆分成词组,这个在网上有现成的组件,比如“庖丁解牛”等,它们大多数是免费开源的。拆成词组之后,应该还要有一个关键词筛选词库,用这个词库确定出有效的词组,比如上图中,“CSDN”、“注册”、“用户”是有效的,而“网站”显然没有匹配,因为它在这句话中没有实际意义。
有点跑题了,拆词、选词不是本文的重点,但却是本文的前提。拿到关键词之后,怎么去数据库中匹配呢?
大家都知道T-SQL中的LIKE语句,通过类似LIKE “%abc%”这样的语法,可以进行模糊匹配,但是它仅仅能进行一次模糊匹配。举个例子:
假如我们确定了a,b,c三个关键词,要查找的记录当然是匹配的越多越好,于是可以这样写:LIKE “%a%b%c%”,这样匹配出的是包含a,b,c三个关键词的记录,但是如果根本没有包含这三个关键词的记录,多只有包含两个的,甚至是只包含一个,那么如何写LIKE语句呢?这样LIKE “%a%b%”?这样LIKE “%a%c%”?这样LIKE “%b%c%”?这样LIKE “%a%”?这样LIKE “%b%”?这样LIKE “%c%”?
显然,需要判断的情况太多,简单的LIKE语句已经无法满足需求。需要注意的是,千万不要试图选出范范的记录,返回到程序中去处理,在程序中处理虽然简单,但是范范的记录,在一个中型系统中,往往能达到千万级别,这么大的数据量,从数据库返回到程序,无疑会给服务器造成相当大的压力。
经过探索,本小菜总结了一个比较简单的方法,暂且称为“LIKE语句多条件贪婪匹配算法”。
算法思想:先用LIKE选出每一组符合一个条件的记录,只选择表的主键。然后把这些记录合并在一起,通过主键分组、统计数量,数量多的,也是匹配多的,后根据数量降序排序,越靠上的记录,匹配的越多。选出匹配的多的记录主键字段,再根据主键去表中选出内容即可。
为了方便大家使用,已经把算法封装成存储过程(直接把下边代码在查询分析器中执行即可)。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com