这个测评的方法是,从输入字符串中选取随机范围的字符附加到它本身。这个测试的有趣之处在于:StringBuffer正是为了执行快速附加而优化的。图 3 显示了这个测评的结果。
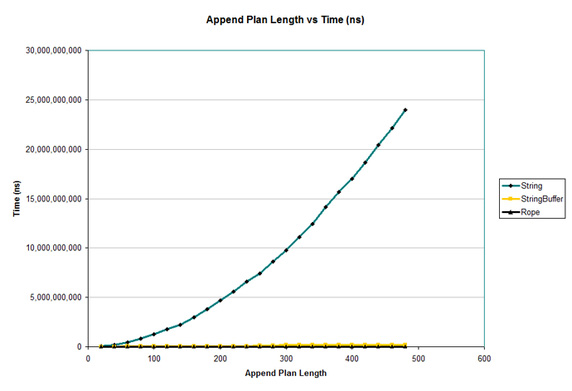
不幸的是,图 3 的视图显示 String的性能非常糟糕。但是,如预期所料,StringBuffer的性能非常好。
图 4 从比较中撤出 String的结果,调整了图表的比例,更清楚地显示了 Rope和 StringBuffer性能的对比。
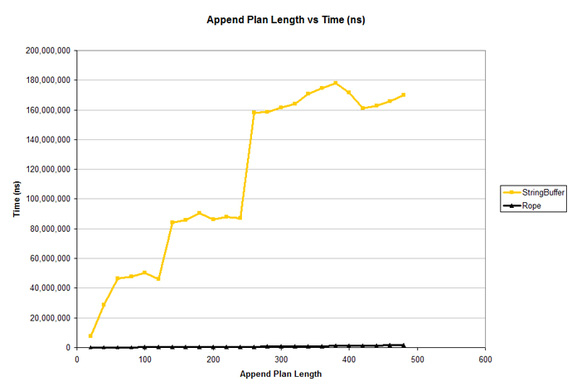
图 4 显示了图 3 中不太明显的 Rope和 StringBuffer之间的巨大区别。Rope很少能突破 x 轴。但是真正有趣的是 StringBuffer的图 —骤然上升后保持稳定上升,而不是平滑地上升。(作为练习,在阅读下一段之前请试着解释一下原因。)
原因与 StringBuffer的空间分配方式有关。它们在其内部数组的末尾分配额外的空间,以便有效地附加字符。但是在空间用尽之后,必须分配全新的数组,并将所有数据复制到新数组。新数组一般根据当前长度调整大小。随着计划长度的增加,生成的 StringBuffer的长度也会增加。随着逐渐到达重新设置大小的阈值,花费的时间也随着额外的重新设置大小和复制而骤升。然后下几个计划长度的性能稳定期(即缓慢提升的时间)也逐渐升高。因为每个计划项增加的字符串长度总数大体相同,所以随后的稳定期比例可以作为重新设置底层数组大小的参考指标。根据这些结果,可以准确地估算出这个 StringBuffer实现大约在 1.5 左右。
结果小结
迄今为止,已经用图表展示了 Rope、String和 StringBuffer之间的性能差异。表 5 提供了所有字符变换测评的计时结果,使用了 480 ?计划长度。
| 变换 / 数据结构 | 时间(单位:纳秒) |
|---|---|
| 插入 | |
String |
18,447,562,195 |
StringBuffer |
6,540,357,890 |
Rope |
31,571,989 |
| 在前部添加 | |
String |
22,730,410,698 |
StringBuffer |
6,251,045,63 |
Rope |
57,748,641 |
| 在后面添加 | |
String |
23,984,100,264 |
StringBuffer |
169,927,944 |
Rope |
1,532,799 |
| 删除(从初始文本中删除 230 个随机范围) | |
String |
162,563,010 |
StringBuffer |
10,422,938 |
Rope |
865,154 |
正则表达式的性能优化
正则表达式在 JDK 1.4 版本中引入,是许多应用程序中广泛使用的一个功能。所以,正则表达式在 rope 中执行良好至关重要。在 Java 语言中,正则表达式用 Pattern表示。要将 Pattern与 CharSequence的区域匹配,要使用模式实例构建 Matcher对象,将 CharSequence作为参数传递给 Matcher。
操纵 CharSequence可为 Java 的正则表达式库提供的灵活性,但也带来了一个严重的缺陷。CharSequence只提供了一个方法来访问它的字符:charAt(x)。像我在概述一节中提到过的,在拥有许多内部节点的 rope 上随机访问字符的时间大约为 O(log n),所以遍历时间为 O(nlog n)。为了演示这个缺陷带来的问题,我测评了在长度为 10,690,488 的字符串中寻找模式 “Crachit*” 的所有实例所花费的时间。所用的 rope 是使用插入测评的同一个变换序列构建的,深度为 65。表 6 显示了测评的结果。
| 技术 | 时间(单位:纳秒) |
|---|---|
String |
75,286,078 |
StringBuffer |
86,083,830 |
Rope |
12,507,367,218 |
重新均衡后的 Rope |
2,628,889,679 |
显然,Rope的匹配性能很差。(明确地讲,对有许多内部节点的 Rope是这样。对于扁平 rope,性能几乎与底层字符表示的性能相同。)即使在显式地均衡过 Rope之后,虽然匹配快了 3.5 倍,Rope的性能还是没有达到与 String或 StringBuffer相同的水平。

