
Oracle Database SQL语句处理步骤
作者:网络转载 发布时间:[ 2012/11/6 9:59:43 ] 推荐标签:
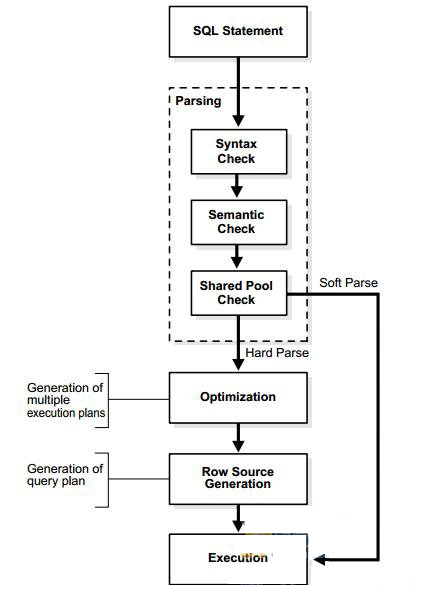
一、解析
1、语法检查
sql语句解析的时候,先执行语法检查。看语句是否符合规范。
2、语义检查
这个阶段,数据库会去判断SQL语句是否真正具有相应的含义,比如说sql语句涉及的表,或者字段是否存在等。
3、shared pool check(shared sql area check)
数据库执行一个shared pool check 去确定它是否可以跳过资源集中的几个步骤。
然后,数据库使用hash算法为每个sql语句生成hash值。那是sql_id v$sql.sql_id.(sql语句shared pool check当匹配到了相同hash value 的时候,还需要其他的检查,比如说语义检查,以及系统环境,比如不同的数据库参数、不同的用户、不同的session环境等,都有可能有影响)
二、优化
在SQL语句的优化阶段,可以分为下面几个步骤。
1、优化器接收解析后的语句,并且生成一组基于sql语句可能的访问路径和hints的执行计划
2、优化器评估每个基于数据字典中统计信息的执行计划的cost。cost 是 预估值。
3、优化器比较并且选择低cost的执行计划。作为查询计划,交给row source 生产器。
优化器的三个主要组件如下图所示:
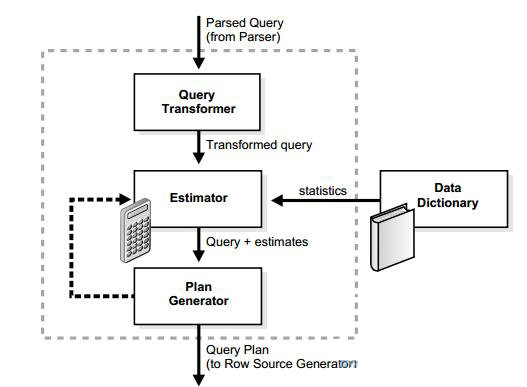
关于这一部分以后的文章中会给出详细的说明。
三、row source generation
它从优化器接收佳的执行计划,并且生成递归计划,叫做查询计划。
递归plan是一个二进制的程序。
当它被sql vm 执行的时候,生成结果集。
查询计划从复杂的步骤中取走一个表格。
每一步都返回一个rowset,这些rowset中的row可以被下一步使用,或者后一步。
其实是可操作的结果集(row set)。它可以是视图,或者连接后的结果集,或者分类操作。
row source generator 生成了一个行源树,它是一个行源的集合。
行源树拥有下面的信息:
1、一个语句引用的表的次序
2、一个语句中提到的每个表的访问方法
3、一个表连接方法的操作影响声明。
4、数据操作,比如说过滤、排序、聚合。
四、执行
执行的时候,sql引擎执行由row source 生成器生成的树中的每一个行源。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com