
用Java日志来写诗
作者:crazyacking 发布时间:[ 2016/7/18 10:43:15 ] 推荐标签:测试开发技术 Java
记录方法的参数和返回值
如果你在开发阶段发现了一个BUG,你通常会用调试器来跟踪具体的原因。现在假设不让你用调试器了,比如,因为这个BUG几天前在用户的环境里出现了,你能拿到的只有一些日志。你能从中发现些什么?
如果你遵循打印每个方法的入参和出参这个简单的原则,你根本不需要调试器。当然每个方法可能访问外部系统,阻塞,等待,等等,这些都应该考虑进来。参考以下这个格式好:
public String printDocument(Document doc, Mode mode) {
log.debug("Entering printDocument(doc={}, mode={})", doc, mode);
String id = ...; //Lengthy printing operation
log.debug("Leaving printDocument(): {}", id);
return id;
}
由于你在方法的开始和结束都记录了日志,所以你可以人工找出效率不高的代码,甚至还可以检测到可能会引起死锁和饥饿的诱因——你只需看一下“Entering”后面是不是没有”Leaving“明白了。如果你的方法名的含义很清晰,清日志将是一件愉快的事情。同样的,分析异常也更得更简单了,因为你知道每一步都在干些什么。代码里要记录的方法很多的话,可以用AOP切面来完成。这样减少了重复的代码,不过使用它得特别小心,不注意的话可能会导致输出大量的日志。
这种日志合适的级别是DEBUG和TRACE了。如果你发现某个方法调用 的太频繁,记录它的日志可能会影响性能的话,只需要调低它的日志级别可以了,或者把日志直接删了(或者整个方法调用只留一个?)不过日志多了总比少了要强。把日志记录当成单元测试来看,你的代码应该布满了日志像它的单元测试到处都是一样。系统没有任何一部分是完全不需要日志的。记住,有时候要知道你的系统是不是正常工作,你只能查看不断刷屏的日志。
观察外部系统
这条建议和前面的有些不同:如果你和一个外部系统通信的话,记得记录下你的系统传出和读入的数据。系统集成是一件苦差事,而诊断两个应用间的问题(想像下不同的公司,环境,技术团队)尤其困难。近我们发现记录完整的消息内容,包括Apache CXF的SOAP和HTTP头,在系统的集成和测试阶段非常有效。
这样做开销很大,如果影响到了性能的话,你只能把日志关了。不过这样你的系统可能跑的很快,挂的也很快,你还无能为力?当和外部系统进行集成的时候,你只能格外小心并做好牺牲一定开销的准备。如果你运气够好,系统集成由ESB处理了,那在总线把请求和响应给记录下来好不过了。可以参考下Mule的这个日志组件。
有时候和外部系统交换的数据量决定了你不可能什么都记下来。另一方面,在测试阶段和发布初期,好把所有东西都记到日志里,做好牺牲性能的准备。可以通过调整日志级别来完成这个。看下下面这个小技巧:
Collection<Integer> requestIds = //...
if(log.isDebugEnabled())
log.debug("Processing ids: {}", requestIds);
else
log.info("Processing ids size: {}", requestIds.size());
如果这个logger是配置成DEBUG级别,它会打印完整的请求ID的集合。如果它配置成了打印INFO信息的话,只会输出集合的大小。你可能会问我是不是忘了isInfoEnabled条件了,看下第二点建议吧。这里还有一个值得注意的是ID的集合不能为null。尽管在DEBUG下,它为NULL也能正常打印,但是当配置成INFO的时候一个大大的空指针。还记得第4点建议中提到的副作用吧?
正确的记录异常
首先,不要记录异常,让框架或者容器来干这个。当然有一个例外:如果你从远程服务中抛出了异常(RMI,EJB等),异常会被序列化,确保它们能返回给客户端 (API中的一部分)。不然的话,客户端会收到NoClassDefFoundError或者别的古怪的异常,而不是真正的错误信息。
异常记录是日志记录的重要的职责之一,不过很多程序员都倾向于把记录日志当作处理异常的方式。他们通常只是返回默认值(一般是null,0或者空字符串),装作什么也没发生一样。还有的时候,他们会先记录异常,然后把异常包装了下再抛出去:
log.error("IO exception", e);
throw new CustomException(e);
这样写通常会把栈信息打印两次,因为捕获了MyCustomException异常的地方也会再打印一次。日志记录,或者包装后再抛出去,不要同时使用,否则你的日志看起来会让人很迷惑。
如果我们真的想记录日志呢?由于某些原因(大概是不读API和文档?),大约有一半的日志记录我认为是错误的。做个小测试,下面哪个日志语句能够正确的打印空指针异常?
try {
Integer x = null;
++x;
} catch (Exception e) {
log.error(e); //A
log.error(e, e); //B
log.error("" + e); //C
log.error(e.toString()); //D
log.error(e.getMessage()); //E
log.error(null, e); //F
log.error("", e); //G
log.error("{}", e); //H
log.error("{}", e.getMessage()); //I
log.error("Error reading configuration file: " + e); //J
log.error("Error reading configuration file: " + e.getMessage()); //K
log.error("Error reading configuration file", e); //L
}
很奇怪吧,只有G和L(这个更好)是对的!A和B在slf4j下面根本编译不过,其它的会把栈跟踪信息给丢掉了或者打印了不正确的信息。比如,E什么也不打印,因为空指针异常本身没有提供任何异常信息而栈信息又没打印出来 .记住,第一个参数通常都是文本信息,关于这个错误本身的。不要把异常信息给写进来,打印日志后它会自动出来的,在栈信息的前面。不过想要打印这个,你当然还得把异常传到第二个参数里面才行。
日志应当可读性强且易于解析
现在有两组用户对你的日志感兴趣:我们人类(不管你同不同意,码农也是在这里边),还有计算机(通常是系统管理员写的shell脚本)。日志应当适合这两种用户来理解。如果有人在你后边看你的程序的日志却看到了这个:
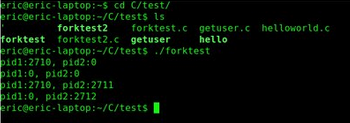
那你肯定没听从我的建议。日志应该像代码一样易于阅读和理解。
另一方面,如果你的程序每小时生成了半GB的日志,没有谁或者任何图形化的文本编辑器能把它们看完。这时候我们的老家伙们,grep,sed和awk这些上场的时候来了。如果有可能的话,你记录的日志好能让人和计算机都能看明白 ,不要将数字格式化,用一些能让正则容易匹配的格式等等。如果不可能的,用两个格式来打印数据:
log.debug("Request TTL set to: {} ({})", new Date(ttl), ttl);
// Request TTL set to: Wed Apr 28 20:14:12 CEST 2010 (1272478452437)
final String duration = DurationFormatUtils.formatDurationWords(durationMillis, true, true);
log.info("Importing took: {}ms ({})", durationMillis, duration);
//Importing took: 123456789ms (1 day 10 hours 17 minutes 36 seconds)
计算机看到”ms after 1970 epoch“这样的的时间格式会感谢你的,而人们则乐于看到”1天10小时17分36秒“这样的东西。
总之,日志也可以写得像诗一样优雅,如果你愿意琢磨的话。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com