
java中常量以及常量池
作者:网络转载 发布时间:[ 2015/12/15 16:09:20 ] 推荐标签:编程语言 测试开发技术
1、举例说明 变量 常量 字面量
1 int a=10;
2 float b=1.234f;
3 String c="abc";
4 final long d=10L;
a,b,c为变量,d为常量 两者都是左值;10,1.234f,"abc",10L都是字面量;
2、常量池:
常量池专门用来用来存放常量的内存区域,常量池分为:静态常量池和运行时常量池;
静态常量池:*.class文件中的常量池,class文件中的常量池不仅仅包含字符串,数值字面量,还包含类、方法的信息,占用class文件绝大部分空间。
运行时常量池:是jvm虚拟机在完成类装载操作后,将class文件中的常量池载入到内存中,并保存在方法区中,我们常说的常量池,是指方法区中的运行时常量池。
备注:java虚拟机内存分为虚拟机栈、虚拟机堆、本地方法栈、程序计数器、方法区(jdk8中,移除了方法区,转而用Metaspace区域替代)
2.1 字符串常量池
1 String s1 = "Hello";
2 String s2 = "Hello";
3 String s3 = "Hel" + "lo";
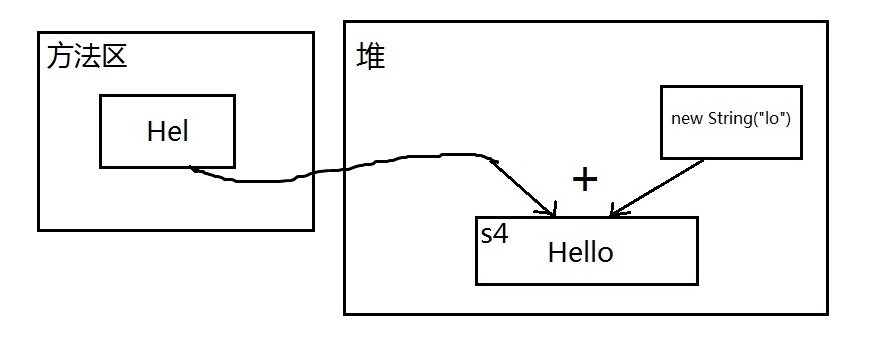
4 String s4 = "Hel" + new String("lo");
5 String s5 = new String("Hello");
6 String s6 = s5.intern();
7 String s7 = "H";
8 String s8 = "ello";
9 String s9 = s7 + s8;
10
11 System.out.println(s1 == s2); // true
12 System.out.println(s1 == s3); // true
13 System.out.println(s1 == s4); // false
14 System.out.println(s1 == s9); // false
15 System.out.println(s4 == s5); // false
16 System.out.println(s1 == s6); // true
java程序经过编译和运行两步:
s1 == s2,编译时,将字面量"Hello"直接放入class文件的常量池中,从而实现复用,载入运行时常量池后,s1、s2指向的是同一个内存地址,所以相等。
s1 == s3,编译时,这种拼接会被优化,编译器直接拼好,在class文件中被优化成String s3 = "Hello";,所以s1 == s3成立。
s1 == s4,编译时,new String("lo") 如何生成 在哪生成还不确定,是一个不可预料的部分,编译器不会优化,必须等到运行时才可以确定结果,所生成后的引用在堆中,而不是方法区,所以地址肯定不同。
s1 == s9 编译时,s7、s8在赋值的时候使用的字符串字面量,但是拼接成s9的时候,s7、s8作为两个变量,都是不可预料的,编译器毕竟是编译器,不可能当解释器用,所以不做优化,等到运行时,s7、s8拼接成的新字符串,在堆中地址不确定,不可能与方法区常量池中的s1地址相同。

jvm常量池,堆,栈内存分布
s4 == s5已经不用解释了,不相等,二者都在堆中,但地址不同。
s1 == s6这两个相等完全归功于intern方法(手工在常量池添加常量),s5在堆中,内容为Hello ,intern方法会尝试将Hello字符串添加到常量池中,并返回其在常量池中的地址,因为常量池中已经有了Hello字符串,所以intern方法直接返回地址;而s1在编译期已经指向常量池了,因此s1和s6指向同一地址,相等。
相关推荐











更新发布
功能测试和接口测试的区别
2023/3/23 14:23:39如何写好测试用例文档
2023/3/22 16:17:39常用的选择回归测试的方式有哪些?
2022/6/14 16:14:27测试流程中需要重点把关几个过程?
2021/10/18 15:37:44性能测试的七种方法
2021/9/17 15:19:29全链路压测优化思路
2021/9/14 15:42:25性能测试流程浅谈
2021/5/28 17:25:47常见的APP性能测试指标
2021/5/8 17:01:11
 sales@spasvo.com
sales@spasvo.com